Link:
https://dannyman.toldme.com/2015/03/06/howto-program-agile/
There seems to be some backlash going on against the religion of “Agile Software Development” and it is best summarized by PragDave, reminding us that the “Agile Manifesto” first places “Individuals and interactions over processes and tools” — there are now a lot of Agile Processes and Tools which you can buy in to . . .
He then summarizes how to work agilely:
What to do:
Find out where you are
Take a small step towards your goal
Adjust your understanding based on what you learned
Repeat
How to do it:
When faced with two or more alternatives that deliver roughly the same value, take the path that makes future change easier.
Sounds like sensible advice. I think I’ll print that out and tape it on my display to help me keep focused.
Feedback Welcome
Link:
https://dannyman.toldme.com/2014/11/22/windows-8-wtf-microsoft/
I had the worst experience at work today: I had to prepare a computer for a new employee. That’s usually a pretty painless procedure, but this user was to be on Windows, and I had to … well, I had to call it quits after making only mediocre progress. This evening I checked online to make sure I’m not insane. A lot of people hate Windows 8, so I enjoyed clicking through a few reviews online, and then I just had to respond to Badger25’s review of Windows 8.1:
I think you are being way too easy on Windows 8.1 here, or at least insulting to the past. This isn’t a huge step backwards to the pre-Windows era: in DOS you could get things done! This is, if anything, a “Great Leap Forward” in which anything that smells of traditional ways of doing things has been purged in order to strengthen the purity of a failed ideology.
As far as boot speed, I was used to Windows XP booting in under five seconds. That was probably the first incarnation of Windows I enjoyed using. I just started setting up a Windows 8 workstation today for a business user and it is the most infuriatingly obtuse Operating System I have ever, in decades, had to deal with. (I am a Unix admin, so I’ve seen things….) This thing does NOT boot fast, or at least it does not reboot fast, because of all the updates which must be slowly applied.
Oddly enough, it seems that these days, the best computer UIs are offered by Linux distros, and they have weird gaps in usability, then Macs, then … I wouldn’t suggest Windows 8 on anyone except possibly those with physical or mental disabilities. Anyone who is used to DOING THINGS with computers is going to feel like they are using the computer with their head wrapped in a hefty bag. The thing could trigger panic attacks.
Monday is another day. I just hope the new employee doesn’t rage quit.
Feedback Welcome
Link:
https://dannyman.toldme.com/2014/10/07/ansible-set-conditional-handler/
I have a playbook which installs and configures NRPE. The packages and services are different on Red Hat versus Debian-based systems, but my site configuration is the same. I burnt a fair amount of time trying to figure out how to allow the configuration tasks to notify a single handler. The result looks something like:
# Debian or Ubuntu
- name: Ensure NRPE is installed on Debian or Ubuntu
when: ansible_pkg_mgr == 'apt'
apt: pkg=nagios-nrpe-server state=latest
- name: Set nrpe_handler to nagios-nrpe-server
when: ansible_pkg_mgr == 'apt'
set_fact: nrpe_handler='nagios-nrpe-server'
# RHEL or CentOS
- name: Ensure NRPE is installed on RHEL or CentOS
when: ansible_pkg_mgr == 'yum'
yum: pkg={{item}} state=latest
with_items:
- nagios-nrpe
- nagios-plugins-nrpe
- name: Set nrpe_handler to nrpe
when: ansible_pkg_mgr == 'yum'
set_fact: nrpe_handler='nrpe'
# Common
- name: Ensure NRPE will talk to Nagios Server
lineinfile: dest=/etc/nagios/nrpe.cfg regexp='^allowed_hosts=' line='allowed_hosts=nagios.domain.com'
notify:
- restart nrpe
### A few other common configuration settings ...
Then, over in the handlers file:
# Common
- name: restart nrpe
service: name={{nrpe_handler}} state=restarted
The trick boiled down to using the set_fact module.
Feedback Welcome
Link:
https://dannyman.toldme.com/2014/05/15/vmware-retina-thunderbolt-constant-resolution/
Apple ships some nice hardware, but the Mac OS is not my cup of tea. So, I run Ubuntu (kubuntu) within VMWare Fusion as my workstation. It has nice features like sharing the clipboard between host and guest, and the ability to share files to the guest. Yay.
At work, I have a Thunderbolt display, which is a very comfortable screen to work at. When I leave my desk, the VMWare guest transfers to the Retina display on my Mac. That is where the trouble starts. You can have VMWare give it less resolution or full Retina resolution, but in either case, the screen size changes and I have to move my windows around.
The fix?
1) In the guest OS, set the display size to: 2560×1440 (or whatever works for your favorite external screen …)
2) Configure VMWare, per https://communities.vmware.com/message/2342718
2.1) Edit Library/Preferences/VMware Fusion/preferences
Set these options:
pref.autoFitGuestToWindow = "FALSE"
pref.autoFitFullScreen = "stretchGuestToHost"
2.2) Suspend your VM and restart Fusion.
Now I can use Exposé to drag my VM between the Thunderbolt display and the Mac’s Retina display, and back again, and things are really comfortable.
The only limitation is that since the aspect ratios differ slightly, the Retina display shows my VM environment in a slight letterbox, but it is not all that obvious on a MacBook Pro.
Feedback Welcome
Link:
https://dannyman.toldme.com/2014/05/14/new-phishing-scam-call-toll-free-to-refresh-your-ip-address/
I reported the following to the FBI, to LogMeIn123.com, to Century Link, and to Bing, and now I’ll share the story with you.
Yesterday, May 12, 2014, a relative was having trouble with Netflix. So she went to Bing and did a search for her ISP’s technical support:
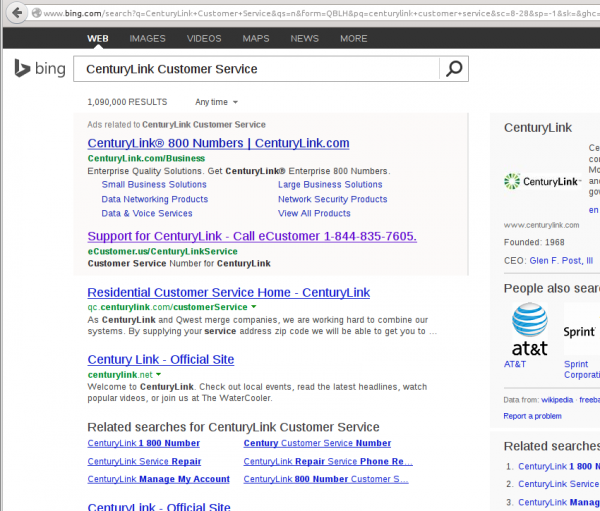
Bing leads you to a convenient toll-free number to call for technical support!
She called the number: 844-835-7605 and spoke with a guy who had her go to LogMeIn123.com so he could fix her computer. He opened up something that revealed to her the presence of “foreign IP addresses” and then showed her the Wikipedia page for the Zeus Trojan Horse. He explained that she would need to refresh her IP address and that their Microsoft Certified Network Security whatevers could do it for $350 and they could take a personal check since her computer was infected and they couldn’t do a transaction online.
So, she conferenced me in. I said that she could just reinstall Windows, but he said no, as long as the IP was infected it would need to be refreshed. I said, well, what if we just destroyed the computer. No, no, the IP is infected. “An IP address is a number: how can it get infected?” I then explained that I was a network administrator . . . he said he would check with his manager. That was the last we heard from him.
I advised her that this sounded very very very much like a phishing scam and that she should call the telephone number on the bill from her ISP. She did that and they were very interested in her experience.
I was initially very worried that she had a virus that managed to fool her into calling a different number for her ISP. I followed up the next day, using similar software to VNC into her computer. I checked the browser history and found that the telephone number was right there in Bing for all the world to see. She doesn’t have a computer virus after all! (I’ll take a cloer look tonight . . .)
I submitted a report to the FBI, LogMeIn123.com, Bing, and Century Link. And now I share the story here. Its a phishing scam that doesn’t even require an actual computer virus to work!
Feedback Welcome
Link:
https://dannyman.toldme.com/2014/04/11/faq-should-i-change-all-my-passwords/
As a SysAdmin, people ask me how much they need to worry over the heartbleed vulnerability. Here’s my own take:

Google were known to be vulnerable. They co-discovered the vulnerability and deployed fixes quickly. I like to believe they are analyzing the scope and likelihood of user password compromise and will issue good advice on whether Gmail passwords should be updated.
For everything else, my small opinion is “don’t panic.” Not every web site would have been affected. The Ops folks at each site need to patch their systems and assess the extent to which credentials may have been compromised, then take appropriate steps to mitigate compromised data, which might include asking users to set new passwords. But if they’re still waiting on some patches, then submitting a new password could actually put both passwords at risk.
For other important passwords, like your bank, check up on what they’re recommending that you do. If a site is important to you and they offer two-factor auth, go for it: that typically means that if you log on from a new computer they’ll text a one-time pin code to your mobile phone to double-check that it’s you.
Feedback Welcome
Link:
https://dannyman.toldme.com/2014/04/02/quick-and-dirty-upstart/
I want to launch a service which has its own complex start/stop script at boot, and I want to launch it as a non-login user. So, I dig into upstart. The cookbook … is not a cookbook. So, here’s is my little recipe:
# /etc/init/openfire.conf
description "Run OpenFire Jabber Server"
start on runlevel [2345]
stop on runlevel [!2345]
setuid openfire
setgid openfire
pre-start exec /opt/openfire/bin/openfire start
post-stop exec /opt/openfire/bin/openfire stop
All this does is, run /opt/openfire/bin/openfire start or /opt/openfire/bin/openfire stop at the appropriate time. Allegedly, this is suboptimal, but it works for me.
I tested with:
sudo start openfire
sudo stop openfire
sudo reboot # :)
Another sample, where the idiom is “cd to a directory and run a command:”
# /etc/init/haste-server.conf
description "Private Pastebin Server"
start on runlevel [2345]
stop on runlevel [!2345]
setuid haste
setgid haste
console log
script
cd /opt/haste-server
npm start
end script
#respawn
Thank you, htorque on askubuntu!
Feedback Welcome
Link:
https://dannyman.toldme.com/2013/11/20/phishing-chinese-domain-registration/
Here is a new phishing attack that made it through to Gmail about the domain name dispute around tjldme . . . ?!!
Dear Manager,
(If you are not the person who is in charge of this, please forward this to your CEO,Thanks)
We are a organization specializing in network consulting and registration in China. Here we have something to confirm with you. We just received an application sent from “Global Importing Co., Ltd” on 20/11/2013, requesting for applying the “tjldme” as the Internet Brand and the following domain names for their business running in China region:
tjldme.asia
tjldme.cn
tjldme.com.cn
tjldme.com.tw
tjldme.hk
tjldme.net.cn
tjldme.org.cn
tjldme.tw
Though our preliminary review and verification, we found that this name is currently being used by your company and is applied as your domain name. In order to avoid any potential risks in terms of domain name dispute and impact on your market businesses in China and Asia in future, we need to confirm with you whether “Global Importing Co., Ltd” is your own subsidiary or partner, whether the registration of the listed domains would bring any impact on you. If no impact on you, we will go on with the registration at once. If you have no relationship with “Global Importing Co., Ltd” and the registration would bring some impact on you, Please contact us immediately within 10 working days, otherwise, you will be deemed as waived by default. We will unconditionally finish the registration for “Global Importing Co., Ltd”
Please contact us in time in order that we can handle this issue better.
Best Regards,
Wesley Hu
Auditing Department.
Registration Department Manager
4/F,No.9 XingHui West Street,
JinNiu ChenDu, China
Office:Â +86 2887662861
Fax:Â +86 2887783286
Web:Â http://www.cnnetpro.com
Please consider the environment before you print this e-mail.
I assume they’ll need a processing fee. I wonder if they munged toldme.com in an effort to avoid Phish filtering . . . ? The URL at the bottom is blocked by our firewall.
1 Comment
Link:
https://dannyman.toldme.com/2013/11/15/a-computer-telephone-without-a-keyboard/
At long last, I retired my old T-Mobile G2. It was the last in a long line of phones I have owned for the past decade with a physical keyboard. (I think I owned every Sidekick up to the 3 before going Android with the G1 and the G2.) I like the ability to thumb type into my phone, but the G2’s old keyboard had long ago gone creaky, and it had lacked a dedicated number row besides.

Obligatory picture recently taken with my new computer telephone. Featuring a cat.
They don’t make nice smart phones with keyboards any more. Market research seems to indicate that the only remaining markets for keyboard phones are horny teenagers who need a cheap, hip Android-based Sidekick, and those legions of high powered business people who will never abandon their ancient Blackberries.
Anyway, the new Nexus 5 is here. The on-screen keyboard is okay slow and inaccurate. Like moving from a really fantastic sports car to a hovercraft piloted by a drunken monkey. I mean,the monkey-piloted hovercraft is undeniably cool technology, and I can eventually get where I need to go, but . . . its not the same, you see?
So, lets explore Voice dictation! It works . . . well, about as well as the monkey hovercraft, but with the added benefit that you don’t have to keep jiggling your thumb across the screen. But how do you do new lines and paragraphs? Where’s the command reference?
I asked Google. Google: android voice dictation commands?
Yup. If there is a reference somewhere, Google doesn’t know about it. How sad.
There is one humorous and not overly annoying video demonstrating how to do voice dictation. Various forum posts have users saying they can’t find a reference, but simple punctuation seems to work, and sometimes you can say “new paragraph” and sometimes you can not.
I have to wonder, at times.
The other thing that excited me about the Nexus 5 was that on the home screen you can drag apps right up to “Uninstall” . . . unless they’re Google apps! “Way to not be evil,” I cried. Until a Google colleague pointed out that it was just a bit of UI funkiness on Google’s part, owing to the applications coming bolted into the UI, there is at least a method to disable them.
Anyway, this is useful knowledge that helped me to vanquish the Picasa sync thing that has been hiding images from the gallery for the past few years. I have another project where I’m testing out BitTorrent Sync to pull images off our phones and then sync a copy of the family photo archive back down to the phones. If that works out, I’ll write it up. I may pursue that further to see if I can’t replace Dropbox, which, unfortunately, does not (yet) offer any sort of a family plan. Also, if I can host my own data I needn’t share as much of it with the NSA.
Feedback Welcome
Link:
https://dannyman.toldme.com/2013/10/15/atlassian-summit/
Two weeks ago, I attended Atlassian Summit 2013 in San Francisco. Â This is an opportunity to train, network, and absorb propaganda about Atlassian products (JIRA, Greenhopper, Confluence, &c.) and ecosystem partners. Â I thought I would share a summary of some of the notes I took along the way, for anyone who might find interest:
At the Keynote, Atlassian launched some interesting products:
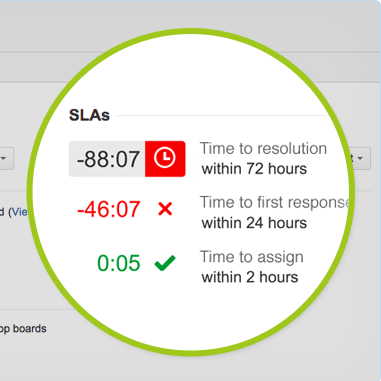
As time passes, the ticket gets crankier at you in real time about the SLA.
Jira Service Desk
Jira Service Desk is an extension to JIRA 6 oriented around IT needs.  The interesting features include:
- Customer Portal with integrated KB search
- Real-time visibility of ticket SLA status
The first thing helps people get their work done, and the second is manager catnip.
Confluence Knowledge Base
Confluence 5.3 features a shake-the-box Knowledge Base setup:
- Improved template system — “blueprints” for different article types
- Real-time search portal which integrates with JIRA Service Desk
- My Questions: enforcing KB link with JIRA workflow and identifying “use count” as an article search metric
Other Stuff I looked into:
REST and Webhooks
There was a presentation on JIRA’s REST API, and mention of Webhooks.
REST is really easy to use.  For example, hit https://jira.atlassian.com/rest/api/latest/issue/JRA-9
There’s API docs here:Â https://docs.atlassian.com/jira/REST/
Another feature for tight integration is Webhooks: you can configure JIRA so that certain issue actions trigger a hit to a remote URL. Â This is generally intended for building apps around JIRA. Â We might use this to implement Nagios ACKs.
Atlassian Connect
I haven’t looked too deeply as this is a JIRA 6 feature, but Atlassian Connect promises to be a new method of building JIRA extensions that is lighter-weight than their traditional plugin method.  (Plugins want you to set up Eclipse and build a Java Dev environment in your workstation… Connect sounds like just build something in your own technology stack around REST and Webhooks)
Cultivating Content: Designing Wiki Solutions that Scale
Rebecca Glassman, a tech writer at Opower, gave a really engaging talk that addresses a problem that seems commonplace: how to tame the wiki jungle! Â Her methodology went something like this:
- Manage the wiki like it is a product: interview stakeholders, get some metrics, do UX testing
- Metrics: Google Analytics, View Tracker Macro, Usage Macro
- UX results at Opower revealed more reliance on Table of Contents vs Search (55%) and that users skip past top-level pages, so you don’t want to put content just on there
- In search, users only look at the first 2-3 results before giving up
- They engaged some users to track the questions they had and their success at getting answers from the wiki
- The Docs people (2) built an “answer desk” situation where they took in Questions from across the company, and tracked their progress writing answers on a Kanban board
As they better learned user needs and what sort of knowledge there was, they built “The BOOK” (Body of Opower Knowledge) based on a National Parks model:
- Most of the wiki is a vast wilderness, which you are free to explore
- The BOOK is the nice, clean visitors center to help take care of most of your needs and help you prepare for your trek into the wilderness
- The BOOK is a handbook, in its own space, with its own look-and-feel, and edits are welcome, but they are vetted by the Docs team via Ad Hoc Workflows
- By having tracked Metrics from the get-go, they can quantify the utility of The BOOK …
(I have some more notes on how they built, launched, and promoted The BOOK. Â The problem they tackled sounds all to familiar and her approach is what I have always imagined as the sort of way to go.)
Ad Hoc Canvas
The Ad Hoc Canvas plugin for Confluence caught my eye.  At first glance, it is like Trello, or Kanban, where you fill out little cards and drag them around to track things.  But it has options to organize the information in different ways depending on the task at hand: wherever you are using a spreadsheet to track knowledge or work, Ad Hoc Canvas might be a much better solution.  Just look at the videos and you get an idea . . .
The Dark Art of Performance Tuning
Adaptavist gave a presentation on performance analysis of JIRA and Confluence. Â It was fairly high-level but the gist of this is that you want to monitor and trend the state of the JVM: memory, heap, garbage collection, filehandles, database connections, &c. Â He had some cool graphs of stuff like garbage collection events versus latency that had helped them to analyze issues for clients. Â One consideration is that each plugin and each code revision to a plugin brings a bunch of new code into the pool with its own potential for issues. Â Ideally, you can set up a load testing environment for your staging system. Â Short of that, the more system metrics that you can track, you can upgrade plugins one at a time and watch for any effects. Â As an example, one plugin upgrade went from reserving 30 database connections to reserving 150 database connections, and that messed up performance because the rest of the system would become starved of available database connections. Â (So, they figured that out and increased that resource..)
tl;dr: JIRA Performance Tuning is a variation of managing other JVM Applications
Collaboration For Executives
I popped in on this session near the end, but the takeaway for anyone who wants to deliver effective presentations to upper management are:
The presenter’s narrative was driven by an initial need to capture executive buy-in that their JIRA system was critical to business function and needed adequate resourcing.
Feedback Welcome
Link:
https://dannyman.toldme.com/2013/09/23/jython-timezone-manipulation-and-meeting-invitations-vs-outlook/
As part of a project at work I’ve built some Jython code that builds iCalendar attachments to include meeting invitations for scheduled maintenance sessions. Jython is Python-in-Java which takes some getting used to but is damned handy when you’re working with JIRA. I will share a few anecdotes:
1) For doing date and time calculations, specifically to determine locale offset from UTC, you’re a lot happier calling the Java SimpleDateFormat stuff than you are dealing with Python. Python is a beautiful language but I burned a lot of time in an earlier version of this code figuring out how to convert between different time objects for manipulation and whatnot. This is not what you would expect from an intuitive, weakly-typed language, and it is interesting to find that the more obtuse, strongly-typed language handles time zones and it just fricking works.
Here is some sample code:
from java.text import SimpleDateFormat
from com.atlassian.jira.timezone import TimeZoneManagerImpl
tzm = TimeZoneManagerImpl(ComponentManager.getInstance().getJiraAuthenticationContext(),
ComponentManager.getInstance().getUserPreferencesManager(),
ComponentManager.getInstance().getApplicationProperties())
# df_utc = DateFormat UTC
# df_assignee = DateFormat Assignee
df_utc = SimpleDateFormat("EEE yyyy-MM-dd HH:mm ZZZZZ (zzz)")
df_assignee = SimpleDateFormat("EEE yyyy-MM-dd HH:mm ZZZZZ (zzz)")
tz = df_utc.getTimeZone()
df_utc.setTimeZone(tz.getTimeZone("UTC"))
df_assignee.setTimeZone(tzm.getTimeZoneforUser(assignee))
issue_dict['Start_Time_text'] = df_utc.format(start_time.getTime())
issue_dict['Start_Time_html'] = df_utc.format(start_time.getTime())
if df_utc != df_assignee:
issue_dict['Start_Time_text'] += "\r\n "
issue_dict['Start_Time_text'] += df_assignee.format(start_time.getTime())
issue_dict['Start_Time_html'] += "
"
issue_dict['Start_Time_html'] += df_assignee.format(start_time.getTime())
# Get TimeZone of Assignee
# Start Time in Assignee TimeZone
Since our team is global I set up our announcement emails to render the time in UTC, and, if it is different, in the time zone of the person leading the change. For example:
| Start Time: |
Mon 2013-09-23 23:00 +0000 (UTC)
Mon 2013-09-23 16:00 -0700 (PDT) |
- We have a team in London. I have not yet tested it but as I understand it, once they leave BST, their timezone is UTC. I am looking forward to seeing if this understanding is correct.
- As I understand it, I’m pulling the current time zone of the user, which changes when we enter and leave DST, which means that the local time will be dodgy when we send an announcement before the cutover for a time after the cut-over.
2) I was sending meeting invitations with the host set to the assignee of the maintenance event. This seemed reasonable to me, but when Mac Outlook saw that the host was set, it would not offer to add the event to the host’s calendar. After all, all meeting invitations come from Microsoft Outlook, right?! If I am the host it must already be on my calendar!!
I tried just not setting the host. This worked fine except now people would RSVP to the event and they would get an error stuck in their outboxes.
So . . . set the host to a bogus email address? My boss was like “just change the code to send two different invitations” which sounds easy enough for him but I know how creaky and fun to debug is my code. I came upon a better solution: I set the host address to user+calendar@domain.com. This way, Outlook is naive enough to believe the email address doesn’t match, but all our software which handles mail delivery knows the old ways of address extension . . . I can send one invitation, and have that much less messy code to maintain.
from icalendar import Calendar, Event, UTC, vText, vCalAddress
# [ . . . ]
event = Event()
# [ . . . ]
# THIS trick allows organizer to add event without breaking RSVP
# decline functionality. (Outlook and its users suck.)
organizer_a = assignee.getEmailAddress().split('@')
organizer = vCalAddress('MAILTO:' + organizer_a[0]+ '+calendar@' +
organizer_a[1])
organizer.params['CN'] = vText(assignee.getDisplayName() + ' (' + assignee.getName() + ')')
event['organizer'] = organizer
You can get an idea of what fun it is to build iCalendar invitations, yes? The thing with the parentheses concatenation on the CN line is to follow our organization’s convention of rendering email addresses as “user@organization.com (Full Name)”.
3) Okay, third anecdote. You see in my first code fragment that I’m building up text objects for HTML and plaintext. I feed them into templates and craft a beautiful mime multipart/alternative with HTML and nicely-formatted plaintext . . . however, if there’s a Calendar invite also attached then Microsoft Exchange blows all that away, mangles the HTML to RTF and back again to HTML, and then renders its own text version of the RTF. My effort to make a pretty text email for the users gets chewed up and spat out, and my HTML gets mangled up, too. (And, yes, I work with SysAdmins so some users actually do look at the plain text . . .) I hate you, Microsoft Exchange!
Feedback Welcome
Link:
https://dannyman.toldme.com/2013/07/18/jython-render-wiki-text-in-jira/
I’m building out a simple template system for our email notifications, so of course I want to support multipart, text and email. But, hey, we have some text fields in JIRA that can take wiki markup, and JIRA will format that on display. So, how do I handle those fields in my text and HTML message attachments?
https://answers.atlassian.com/questions/191567/in-a-jira-script-how-do-i-render-wiki-text-fields
https://answers.atlassian.com/questions/135084/method-to-convert-jira-wiki-format-to-html
So, some sample code to render the custom field “Change Summary” into a pair of strings, change_summary_text and change_summary_html, suitable for inclusion into an email message:
from com.atlassian.event.api import EventPublisher
from com.atlassian.jira import ComponentManager
from com.atlassian.jira.component import ComponentAccessor
from com.atlassian.jira.issue import CustomFieldManager
from com.atlassian.jira.issue.fields import CustomField
from com.atlassian.jira.issue.fields.renderer.wiki import AtlassianWikiRenderer
from com.atlassian.jira.util.velocity import VelocityRequestContextFactory
# Get Custom Field
cfm = ComponentManager.getInstance().getCustomFieldManager()
change_summary = issue.getCustomFieldValue(cfm.getCustomFieldObjectByName("Change Summary"))
# Set up Wiki renderer
eventPublisher = ComponentAccessor.getOSGiComponentInstanceOfType(EventPublisher)
velocityRequestContextFactory = ComponentAccessor.getOSGiComponentInstanceOfType(VelocityRequestContextFactory)
wikiRenderer = AtlassianWikiRenderer(eventPublisher, velocityRequestContextFactory)
# Render Custom Field
change_summary_html = wikiRenderer.render(change_summary, None)
change_summary_text = wikiRenderer.renderAsText(change_summary, None)
Feedback Welcome
Link:
https://dannyman.toldme.com/2013/05/22/p4-move-files/
Some quick notes. I wanted to move my existing *.py files for JIRA to a subdirectory. I had a bit of a time figuring this out, so maybe this will help someone when googling on the issue:
p4 sync
mkdir -p jython/workflow
p4 edit *.py
bash # I use tcsh
for f in *.py; do
p4 move $f jython/workflow/$f
done
exit # Back to tcsh
p4 submit
Feedback Welcome
Link:
https://dannyman.toldme.com/2013/05/13/embed-page-refresh/
Feature request that certain JIRA dashboards should reload more frequently than every fifteen minutes. So, I cooked up some JavaScript to hide in the announcement banner:
Now users can add refresh=nn and the page will reload every nn seconds. This ought to work in most cases where you can sneak some HTML into a Web App.
Function gup stolen from http://stackoverflow.com/questions/979975/how-to-get-the-value-from-url-parameter.
Feedback Welcome
Link:
https://dannyman.toldme.com/2013/04/19/vmware-workstation-excessive-key-repeating-in-ubuntu-guest/
I like to virtualize my workstation using VMWare Workstation. Lately, my Ubuntu (kubuntu) 12.04 guest would exhibit really annoying behavior whereby it would insert lots of extra letters as I typed, seemingly at random.
I cast about a few times for a fix. I tried VMWare KB 196, and a few solutions offered in an abandoned blog. But what did the trick is good old xset.
I added this to my .bashrc:
xset r rate 500 20
As I understand it, this means “key repeat only happens if you hold a key down for at least half a second, and then not for more than 20 times.”
My workstation has been way more pleasant to deal with ever since.
Feedback Welcome
« Newer Stuff . . . Older Stuff »
Site Archive
