I’ve been a SysAdmin for … since the last millennium. Long enough to see certain fads come and go and come again. There was a time when folks got keen on the advantages of chroot jails, but that time faded, then resurged in the form of containers! All the rage!
My own bias is that bare metal systems and VMs are what I am used to: a Unix SysAdmin knows how to manage systems! The advantages and desire for more contained environments seems to better suit certain types of programmers, and I suspect that the desire for chroot-jail-virtualenv-containers may be a reflection of programming trends.
On the one hand, you’ve got say C and Java … write, compile, deploy. You can statically link C code and put your Java all in a big jar, and then to run it on a server you’ll need say a particular kernel version, or a particular version of Java, and some light scaffolding to configure, start/stop and log. You can just write up a little README and hand that stuff off to the Ops team and they’ll figure out the mysterious stuff like chmod and the production database password. (And the load balancer config..eek!)
On the other hand, if you’re hacking away in an interpreted language: say Python or R, you’ve got a growing wad of dependencies, and eventually you’ll get to a point where you need the older version of one dependency and a bleeding-edge version of another and keeping track of those dependencies and convincing the OS to furnish them all for you … what comes in handy is if you can just wad up a giant tarball of all your stuff and run it in a little “isolated” environment. You don’t really want to get Ops involved because they may laugh at you or run in terror … instead you can just shove the whole thing in a container, run that thing in the cloud, and now without even ever having to understand esoteric stuff like chmod you are now DevOps!
(Woah: Job Security!!)
From my perspective, containers start as a way to deploy software. Nowadays there’s a bunch of scaffolding for containers to be a way to deploy and manage a service stack. I haven’t dealt with either case, and my incumbent philosophy tends to be “well, we already have these other tools” …
Container Architecture is basically just Legos mixed with Minecraft (CC: Wikipedia)
Anyway, as a Service Provider (… I know “DevOps” is meant to get away from that ugly idea that Ops is a service provider …) I figure if containers help us ship the code, we’ll get us some containers, and if we want orchestration capabilities … well, we have what we have now and we can look at bringing up other new stuff if it will serve us better.
ASIDE: One thing that has put me off containers thus far is not so much that they’re reinventing the wheel, so much that I went to a DevOps conference a few years back and it seemed every single talk was about how we have been delivered from the evil sinful ways of physical computers and VMs and the tyranny of package managers and chmod and load balancers and we have found the Good News that we can build this stuff all over in a new image and it will be called Docker or Mesos or Kubernetes but careful the API changed in the last version but have you heard we have a thing called etcd which is a special thing to manage your config files because nobody has ever figured out an effective way to … honestly I don’t know for etcd one way or another: it was just the glazed, fervent stare in the eyes of the guy who was explaining to me the virtues of etcd …
It turns out it is not just me who is a curmudgeonly contrarian: a lot of people are freaked out by the True Believers. But that needn’t keep us from deploying useful tools, and my colleague reports that Kubernetes for containers seems awfully similar to the Ganeti we are already running for VMs, so let us bootstrap some infrastructure and provide some potentially useful services to the development team, shall we?
I recently started using sslmate to manage SSL certificates. SSL is one of those complicated things you deal with rarely so it has historically been a pain in the neck.
But sslmate makes it all easy … you install the sslmate command and can generate, sign, and install certificates from the command-line. You then have to check your email when getting a signed cert to verify … and you’re good.
The certificates auto-renew annually, assuming you click the email. I did this for an important cert yesterday. Another thing you do (sslmate walks you through all these details) is set up a cron.
This morning at 6:25am the cron got run on our servers … with minimal intervention (I had to click a confirmation link on an email yesterday) our web servers are now running on renewed certs …. one less pain in the neck.
So … next time you have to deal with SSL I would say “go to sslmate.com and follow the instructions and you’ll be in a happy place.”
Aaaand, you want to set up passwordless SSH for the remote hosts in your Ansible. There are lots of examples that involve file lookups for blah blah blah dot pub but why not just get a list from the agent?
A playbook:
- hosts: all
gather_facts: no
tasks:
- name: Get my SSH public keys
local_action: shell ssh-add -L
register: ssh_keys
- name: List my SSH public keys
debug: msg="{{ ssh_keys.stdout }}"
- name: Install my SSH public keys on Remote Servers
authorized_key: user={{lookup('env', 'USER')}} key="{{item}}"
with_items: "{{ ssh_keys.stdout }}"
The two tricky bits are:
1) Running a local_action to get a list of SSH keys.
2) Doing with_items to iterate if there are multiple keys.
A bonus tricky bit:
3) You may need to install sshpass if you do not already have key access to the remote servers. Last I knew, the brew command on Mac OS will balk at you for trying to install this.
I have misplaced my coffee mug. I’m glad to hear Ubuntu 16.04 LTS is out. “Codenamed ‘Xenial Xerus'” because computer people don’t already come off as a bunch of space cadets. Anyway, an under-caffeinated curmudgeon’s take:
The Linux kernel has been updated to the 4.4.6 longterm maintenance
release, with the addition of ZFS-on-Linux, a combination of a volume
manager and filesystem which enables efficient snapshots, copy-on-write
cloning, continuous integrity checking against data corruption, automatic
filesystem repair, and data compression.
Ah, ZFS! The last word in filesystems! How very exciting that after a mere decade we have stable support for it on Linux.
There’s a mention of the desktop: updates to LibreOffice and “stability improvements to Unity.” I’m not going to take that bait. No sir.
Ubuntu Server 16.04 LTS includes the Mitaka release of OpenStack, along
with the new 2.0 versions of Juju, LXD, and MAAS to save devops teams
time and headache when deploying distributed applications – whether on
private clouds, public clouds, or on developer laptops.
I honestly don’t know what these do, but my hunch is that they have their own overhead of time and headache. Fortunately, I have semi-automated network install of servers, Ganeti to manage VMs, and Ansible to automate admin stuff, so I can sit on the sidelines for now and hope that by the time I need it, Openstack is mature enough that I can reap its advantages with minimal investment.
Aside: My position on containers is the same position I have on Openstack, though I’m wondering if the containers thing may blow over before full maturity. Every few years some folks get excited about the possibility of reinventing their incumbent systems management paradigms with jails, burn a bunch of time blowing their own minds, then get frustrated with the limitations and go back to the old ways. We’ll see.
Anyway, Ubuntu keeps delivering:
Ubuntu 16.04 LTS introduces a new application format, the ‘snap’, which
can be installed alongside traditional deb packages. These two packaging
formats live quite comfortably next to one another and enable Ubuntu to
maintain its existing processes for development and updates.
YES YES YES YES YES YES YES OH snap OH MY LERD YES IF THERE IS ONE THING WE DESPERATELY NEED IT IS YET ANOTHER WAY TO MANAGE PACKAGES I AM TOTALLY SURE THESE TWO PACKAGING FORMATS WILL LIVE QUITE COMFORTABLY TOGETHER next to the CPANs and the CRANs and the PIPs and the … don’t even ask how the R packages work …
Further research reveals that they’ve replaced Python 2 with Python 3. No mention of that in the email announcement. I’m totally sure this will not yield any weird problems.
I am having a tricky time with Ganeti, and the mailing list is not proving helpful. One factor is that I have two different versions in play. How does one divine the differences between these versions?
Git to the rescue! Along these lines:
git clone git://git.ganeti.org/ganeti.git # Clone the repo ...
cd ganeti
git branch -a # See what branches we have
git ls-remote --tags # See what tags we have
git checkout tags/v2.12.4 # Check out the "old" branch/tag
git diff tags/v2.12.6 # Diff "old" vs "new" branch/tag
# OH WAIT, IT IS EVEN EASIER THAN THIS! (Thanks, candlerb!)
# You don't hack to check out a branch, just do this:
git diff v2.12.4 v2.12.6 # Diff "old" vs "new"
And now I see the “diff” between 2.12.4 and 2.12.6, and the changes seem relevant to my issue.
In my mind, what is most unfortunate about that setup, is they did not get to experience Dial Up Networking via a modem. I think they would have been truly blown away. Alas, the Internet contains wonders, like this guy getting a 50 year old modem to work:
What could be more amazing than that? How about this guy, with a 50 year old modem and a teletype, browsing the first web site via the first web browser, by means of a punch tape bookmark?
I wanted to share a clever load balancer config strategy I accidentally discovered. The use case is you want to make a web service available to clients on the Internet. Two things you’ll need are:
1) an authentication mechanism
2) encrypted transport (HTTPS)
You can wrap authentication around an arbitrary web app with HTTP auth. Easy and done.
For encrypted transport of web traffic, I now love sslmate is the greatest thing since sliced bread. Why?
1) Inexpensive SSL certs.
2) You order / install the certs from a command line.
3) They feed you the conf you probably need for your software.
4) Then you can put the auto-renew in cron.
So, for example, an nginx set up to answer on port 443, handle the SSL connection, do http auth, then proxy over to the actual service, running on port 12345:
The clever load balancer config? The health check is to hit the server(s) in the pool, request / via HTTPS, and expect a 401 response. The load balancer doesn’t know the application password, so if you don’t let it in, you must be doing something right. If someone mucks with the server configuration and disables HTTP AUTH, then the load-balancer will get 200 on its health checks, regard success as an error, and “fail safe” by taking the server out of the pool, thus preventing people from accessing the site without a password.
Tell the load balancer that success is not an acceptable outcome
One of my personal “best practices” is to leave myself and my colleagues hints as to how to get the job done. Plenty of folks may be aware that they need to edit /etc/exports to add a client to an NFS server. I would guess that the filename and convention is decades old, but who among us, even the full-time Unix guy, recalls that you then need to reload the nfs-kernel-server process?
For example:
0-11:04 djh@fs0 ~$ head -7 /etc/exports
# /etc/exports: the access control list for filesystems which may be exported
# to NFS clients. See exports(5).
#
# ***** HINT: After you edit this file, do: *****
# sudo service nfs-kernel-server reload
# ***** HINT: run the command on the previous line! *****
#
The other day I figured to browse Best Buy. I spied a 15″ Toshiba laptop, the kind that can pivot the screen 180 degrees into a tablet. With a full sized keyboard. And a 4k screen. And 12GB of RAM. For $1,000. The catch? A non-SSD 1TB hard drive and stock graphics. And … Windows 10.
But it appealed to me because I’ve been thinking I want a computer I can use on the couch. My home workstation is very nice, a desktop with a 4k screen, but it is very much a workstation. Especially because of the 4k screen it is poorly suited to sitting back and browsing … so, I went home, thought on it over dinner, then drove back to the store and bought a toy. (Oh boy! Oh boy!!)
Every few years I flirt with Microsoft stuff — trying to prove that despite the fact I’m a Unix guy I still have an open mind. I almost usually throw up my hands in exasperation after a few weeks. The only time I ever sort of appreciated Microsoft was around the Windows XP days, it was a pretty decent OS managing folders full of pictures. A lot nicer than OS X, anyway.
This time, out of the gate, Windows 10 was a dog. The non-SSD hard drive slowed things down a great deal. Once I got up and running though, it isn’t bad. It took a little getting used to the sluggishness — a combination of my adapting to the trackpad mouse thing and I swear that under load the Windows UI is less responsive than what I’m used to. The 4k stuff works reasonably well … a lot of apps are just transparently pixel-doubled, which isn’t always pretty but it beats squinting. I can flip the thing around into a landscape tablet — which is kind of nice, though, given its size, a bit awkward — for reading. I can tap the screen or pinch around to zoom text. The UI, so far, is back to the good old Windows-and-Icons stuff old-timers like me are used to.
Mind you, I haven’t tried anything as nutty as setting up OpenVPN to auto-launch on user login. Trying to make that happen for one of my users at work on Windows 8 left me twitchy for weeks afterward.
Anyway, a little bit of time will tell .. I have until January 15 to make a return. The use case is web browsing, maybe some gaming, and sorting photos which are synced via Dropbox. This will likely do the trick. As a little bonus, McAfee anti-virus is paid for for the first year!
I did try Ubuntu, though. Despite UEFI and all the secure boot crud, Ubuntu 15.10 managed the install like it was nothing, re-sizing the hard drive and all. No driver issues … touchscreen even worked. Nice! Normally, I hate Unity, but it is okay for a casual computing environment. Unlike Windows 10, though, I can’t three-finger-swipe-up to show all the windows. Windows+W will do that but really … and I couldn’t figure out how to get “middle mouse button” working on the track pad. For me, probably 70% of why I like Unix as an interface is the ease of copy-paste.
But things got really dark when I tried to try KDE and XFCE. Installing either kubuntu-desktop or xubuntu-desktop actually made the computer unusable. The first had a weird package conflict that caused X to just not display at all. I had to boot into safe mode and manually remove the kubuntu dependencies. The XFCE was slightly less traumatic: it just broke all the window managers in weird ways until I again figured out how to manually remove the dependencies.
It is just as easy to pull up a Terminal on Windows 10 or Ubuntu … you hit Start and type “term” but Windows 10 doesn’t come with an SSH client, which is all I really ask. From what I can tell, my old friend PuTTY is still the State of the Art. It is like the 1990s never died.
Ah, and out of the gate, Windows 10 allows you multiple desktops. Looks similar to Mac. I haven’t really played with it but it is a heartening sign.
And the Toshiba is nice. If I return it I think I’ll look for something with a matte screen and maybe actual buttons around the track pad so that if I do Unix it up, I can middle-click. Oh, and maybe an SSD and nicer graphics … but you can always upgrade the hard drive after the fact. I prefer matte screens, and being a touch screen means this thing hoovers up fingerprints faster than you can say chamois.
Maybe I’ll try FreeBSD on the Linux partition. See how a very old friend fares on this new toy. :)
$ for s in a b c d; do echo ; echo sd${s} ; sudo dd if=/dev/sd${s} of=/dev/null; done
sda
3907029168+0 records in
3907029168+0 records out
2000398934016 bytes (2.0 TB) copied, 17940.3 s, 112 MB/s
sdb
3907029168+0 records in
3907029168+0 records out
2000398934016 bytes (2.0 TB) copied, 15457.9 s, 129 MB/s
sdc
3907029168+0 records in
3907029168+0 records out
2000398934016 bytes (2.0 TB) copied, 15119.4 s, 132 MB/s
sdd
3907029168+0 records in
3907029168+0 records out
2000398934016 bytes (2.0 TB) copied, 16689.7 s, 120 MB/s
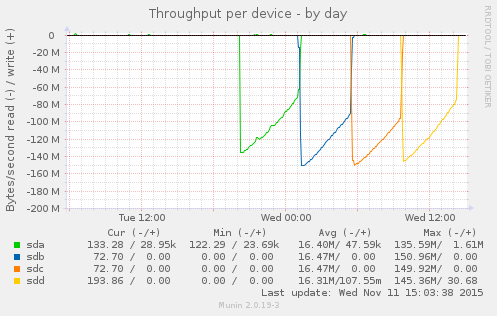
The back story is that I had a system with two bad disks, which seems a little weird. I replaced the disks and I am trying to kick some tires before I put the system back into service. The loop above says “read each disk in turn in its entirety.” Prior to replacing the disks, a loop like the above would cause the bad disks, sdb, and sdc, to abort read before completing the process.
The disks in this system are 2TB 7200RPM SATA drives. sda and sdd are Western Digital, while sdb and sdc are HGST. This is in no way intended as a benchmark, but what I appreciate is the consistent pattern across the disks: throughput starts high and then gradually drops over time. What is going on? Well, these are platters of magnetic discs spinning at a constant speed. When you read a track on the outer part of the platter, you get more data than when you read from closer to the center.
I appreciate the clean visual illustration of this principle. On the compute cluster, I have noticed that we are more likely to hit performance issues when storage capacity gets tight. I had some old knowledge from FreeBSD that at a certain threshold, the OS optimizes disk writes for storage versus speed. I don’t know if Linux / ext4 operates that way. It is reassuring to understand that, due to the physical properties, traditional hard drives slow down as they fill up.
I have been loath to embrace containers, especially since I attended a conference that was supposed to be about DevOps but was 90% about all the various projects around Docker and the like. I worked enough with Jails in the past two decades to feel exasperation at the fervent religious belief of the advantages of reinventing an old wheel.
I attended a presentation about Kubernetes yesterday. Kubernetes is an orchestration tool for containers that sounds like a skin condition, but I try to keep an open mind. “Watch how fast I can re-allocate and scale my compute resources!” Well, I can do that more slowly but conveniently enough with my VM and config management tools . . .
There was an undercurrent there that Kubernetes is the Great New Religion that Will Unify All the Things. I used to embrace ideas like that, then I got really turned off by thinking like that, and now I know enough to see through the True Beliefs. I could deploy Kubernetes as an offering of my IT “Service Catalog” as a complimentary option versus the bare metal, hadoopclusters, VM, and otherservices I have to offer. It is not a Winner Take All play, but an option that could improve productivity for some of our application deployment needs.
At the end of the day, as an IT Guy, I need to be a good aggregator, offering my users a range of solutions and helping them adopt more useful tools for their needs. My metrics for success are whether or not my solutions work for my users, whether they further the mission of my enterprise, and whether they are cost-effective, in terms of time and money.
Early in my career, I didn’t interact much with management. For the past decade, the companies I have worked at had regular one-on-one meetings with my immediate manager. At the end of my tenure at Cisco, thanks to a growing rapport and adjacent cubicles, I communicated with my manager several times a day, on all manner of topics.
One of the nagging questions I’ve never really asked myself is: what is the point of a one-on-one? I never really looked at it beyond being a thing managers are told to do, a minor tax on my time. At Cisco, I found value in harvesting bits of gossip as to what was going in the levels of management between me and the CEO.
Ben Horowitz has a good piece on his blog. In his view, the one-on-one is an important end point of an effective communication architecture within the company. The employee should drive the agenda, perhaps to the point of providing a written agenda ahead of time. “This is what is on my mind,” giving management an opportunity to listen, refine strategies, clarify expectations, un-block, and provide insight up the management chain. He suggests some questions to help get introverted employees talking.
I am not a manager, but as an employee, the take-away is the need to conjure an agenda: what is working? What is not working? How can we make not merely the technology, but the way we work as a team and a company, more effective?
ServerA> virsh -c qemu:///system list
Id Name State
----------------------------------------------------
5 testvm0 running
ServerA> virsh -c qemu+ssh://ServerB list # Test connection to ServerB
Id Name State
----------------------------------------------------
The real trick is to work around a bug whereby the target disk needs to be created. So, on ServerB, I created an empty 8G disk image:
This will take some time. I used virt-manager to attach to testvm0’s console and ran a ping test. At the end of the procedure, virt-manager lost console. I reconnected via ServerB and found that the VM hadn’t missed a ping.
And now:
ServerA> virsh -c qemu+ssh://ServerB/system list
Id Name State
----------------------------------------------------
4 testvm0 running
Admittedly, the need to manually create the target disk is a little more janky than I’d like, but this is definitely a nice proof of concept and another nail in the coffin of NAS being a hard dependency for VM infrastructure. Any day you can kiss expensive, proprietary SPOF dependencies goodbye is a good day.
I inherited a bunch of ProxMox. It is a rather nice, freemium (nagware) front-end to virtualization in Linux. One of my frustrations is that the local NAS is pretty weak, so we mostly run VMs on local disk. That compounds with another frustration where ProxMox doesn’t let you build local RAID on the VM hosts. That is especially sad because it is based on Debian and at least with Ubuntu, building software RAID at boot is really easy. If only I could easily manage my VMs on Ubuntu . . .
And then, on your local Ubuntu workstation: (you are a SysAdmin, right?)
sudo apt-get install virt-manager
Then, upon running virt-manager, you can connect to the remote host(s) via SSH, and, whee! Full console access! So far the only kink I have had to iron is that for guest PXE boot you need to switch Source device to vtap. The system also supports live migration but that looks like it depends on a shared network filesystem. More to explore.
I have been working with AWS to automate disaster recovery. Sync data up to S3 buckets (or, sometimes, EBS) and then write Ansible scripts to deploy a bunch of EC2 instances, restore the data, configure the systems.
Restoring data from Glacier is kind of a pain to automate. You have to iterate over the items in a bucket and issue restore requests for each item. But it gets more exciting than that on the billing end: Glacier restores can be crazy expensive!
2) Amazon Glacier will also charge you money if you delete data that hasn’t been in there for at least three months. If you Glacier something, you will pay to store it for at least three months. So, Glacier your archive data, but for something like a rolling backup, no Glacier.
3) When you get a $,$$$ bill one month because you were naive, file a support request and they can get you some money refunded.


{kind=link}
{kind=link}