Back in the 90s I bought a modem off a guy in California. In those days if you bought something from a guy on the Internet it was a leap of faith that you’d send off a check and get what you expected in return. Well, I sent this guy my money and he sent off the modem and the next day he sent this apology that he had forgotten to pack the power brick, which he had sent off in a separate package. No sweat. The modem showed up at my house a week later.
But the power brick … well, we kept up correspondence but it never showed up until a couple months later the guy said it had arrived back at his house without explanation, covered in mysterious markings from the Post Office, so he packed the mystery package into a bigger box and mailed that off to Illinois and it showed up a few days later and I had a working modem.
In those days I was in college, and when I got tired of school I worked at an ISP, and when I got tired of working I finally finished school. One of my hobbies was keeping an, ahem, online journal. I would have my fairly banal young guy adventures and sometimes when I couldn’t sleep or just needed to talk about things I would write things up in my, ahem, online journal. In those days, the universe of people you knew and the universe of people who read your online journal would barely overlap. There was a certain anonymous freedom, but whatever.
After I paid for my modem, it became the pattern that when I would post another update online, some hours or days later I would get a long rambling email from this dude in California, who was excited to read what I was up to, and he’d tell me about his own adventures, some from his youth … he once had a girl who smelled like cardboard, which he never could figure out … or more often about how he had just biked down to Pismo Beach with his wife Dana.
I had a fan.
And for years, whenever I would post about my life, this guy would write me back, with his own stories.
As my school wound down I got an interview in the San Francisco area, at a start-up. The start-up flew me out and after the interview, the co-founder drove me up to Pinole so I could crash at MikeyA’s place. I finally met the man. Mike Austin. I slept on his couch. He took me over to Fisherman’s Wharf, where I impressed him by eating a second dinner. He drove me around Pinole and San Pablo, showing me his spots and his friends, the liquor store where he sometimes worked.
He put me up another time, years later, on my second move to California, that time with a new wife.
He was a former cop, who worked odd jobs: liquor store, truck driver, but mostly it seemed he was having his own adventures, touring the States on his Harley, or small adventures close to home with innumerable friends. He told me a lot of guys had taken turns sleeping at his place. A lot of cop friends, who had been thrown out of the house by their wives. He is that kind of guy.
I was impressed by his ZZ Top style beard. The story he told me, and I prefer to believe it, is that he’d shave it down once a year but it always grew right back in proud and long. So it goes.
Another time he told me about how he upset his doctor. He went in for a regular checkup but his labs came back off the charts for diabetes. They drew another set of labs and he was normal. What? Well, what did you eat before the first visit? This, that, and two liters of Mountain Dew … his doctor delivered a lecture on how one should not drink two liters of Mountain Dew at lunch … or ever.
Anyway, MikeyA, Mike Austin, my Number One Fan, well, he passed away last week. In his sleep. At 65 years of age. These are hard times for his wife, Dana, no doubt. I’m going to miss the guy, too. I don’t tell rambling stories about my life on the Internet these days, and it has been a while since I got a good rambling email from Mike. I’ll still have the occasional late-night heart-to-heart with the Internet. No more emails from MikeyA, though.
Anyway, I thought I would “remember” him in the way I knew him. By just writing up some thoughts and sharing them here, with you, and with Mikey. If there is an afterlife, I assume he’s read this by now. I miss you, Mike!
Apple’s new “Spaceship” in Cupertino contains 318,000 m2 of offices and 325,000 m2 of parking.
Cupertino, the suburban city where the new headquarters is located, demands it. Cupertino has a requirement for every building. A developer who wants to put up a block of flats, for example, must provide two parking spaces per apartment, one of which must be covered. For a fast-food restaurant, the city demands one space for every three seats; for a bowling alley, seven spaces per lane plus one for every worker. Cupertino’s neighbours have similar rules. With such a surfeit of parking, most of it free, it is little wonder that most people get around Silicon Valley by car, or that the area has such appalling traffic jams.
Cars sit idle 95% of the time.
Water companies are not obliged to supply all the water that people would use if it were free, nor are power companies expected to provide all the free electricity that customers might want. But many cities try to provide enough spaces to meet the demand for free parking, even at peak times. Some base their parking minimums on the “Parking Generation Handbookâ€, a tome produced by the Institute of Transportation Engineers. This reports how many cars are found in the free car parks of synagogues, waterslide parks and so on when they are busiest.
Car parking takes up space. Parking lots dominate the downtown area of Kansas City, MO. As space gets stretched out, walking and bicycling lose their appeal. “Besides, if you know you can park free wherever you go, why not drive?”
The rule of thumb in America is that multi-storey car parks cost about $25,000 per space and underground parking costs $35,000. Donald Shoup, an authority on parking economics, estimates that creating the minimum number of spaces adds 67% to the cost of a new shopping centre in Los Angeles if the car park is above ground and 93% if it is underground. Parking requirements can also make redevelopment impossible. Converting an old office building into flats generally means providing the parking spaces required for a new block of flats, which is likely to be difficult. The biggest cost of parking minimums may be the economic activity they prevent.
There Is No Such Thing As A Free Lunch: everyone pays for free parking:
And that has an unfortunate distributional effect, because young people drive a little less than the middle-aged and the poor drive less than the rich. In America, 17% of blacks and 12% of Hispanics who lived in big cities usually took public transport to work in 2013, whereas 7% of whites did. Free parking represents a subsidy for older people that is paid disproportionately by the young and a subsidy for the wealthy that is paid by the poor.
When autonomous cars become available, many will likely operate like taxis. Less parking will be needed for homes and businesses. There will be more demand for drop-off and pick-up areas. There will be more demand for service garages, where the autonomous cars can go to charge, clean, and receive maintenance.
Existing parking minimums, which provide a subsidy for individual car ownership, will retard the adoption of autonomous vehicles in the United States. Personal vehicles will be subject to a parking subsidy, whereas autonomous car operators will need to supply maintenance garages at their expense. See Also: streetcars versus buses, railroads versus trucking.
Market-rate parking permits for public streets are logical, but culturally unpopular, even in transit-based European cities like Amsterdam.
The result is a perpetual scrap for empty kerb. As San Francisco’s infuriated drivers cruise around, they crowd the roads and pollute the air. This is a widespread hidden cost of under-priced street parking. Mr Shoup has estimated that cruising for spaces in Westwood village, in Los Angeles, amounts to 950,000 excess vehicle miles travelled per year. Westwood is tiny, with only 470 metered spaces.
In the 1950s, while Japan was still poor, Tokyo required motorists to show proof of access to a dedicated parking space. There is no overnight street parking in Tokyo.
Freed of cars, the narrow residential streets of Tokyo are quieter than in other big cities. Every so often a courtyard or spare patch of land has been turned into a car park—some more expensive than others. Once you become accustomed to the idea that city streets are only for driving and walking, and not for parking, it is difficult to imagine how it could possibly be otherwise. Mr Kondoh is so perplexed by an account of a British suburb, with its kerbside commons, that he asks for a diagram. Your correspondent tries to draw his own street, with large rectangles for houses, a line representing the kerb and small rectangles showing all the parked cars. The small rectangles take up a surprising amount of room.
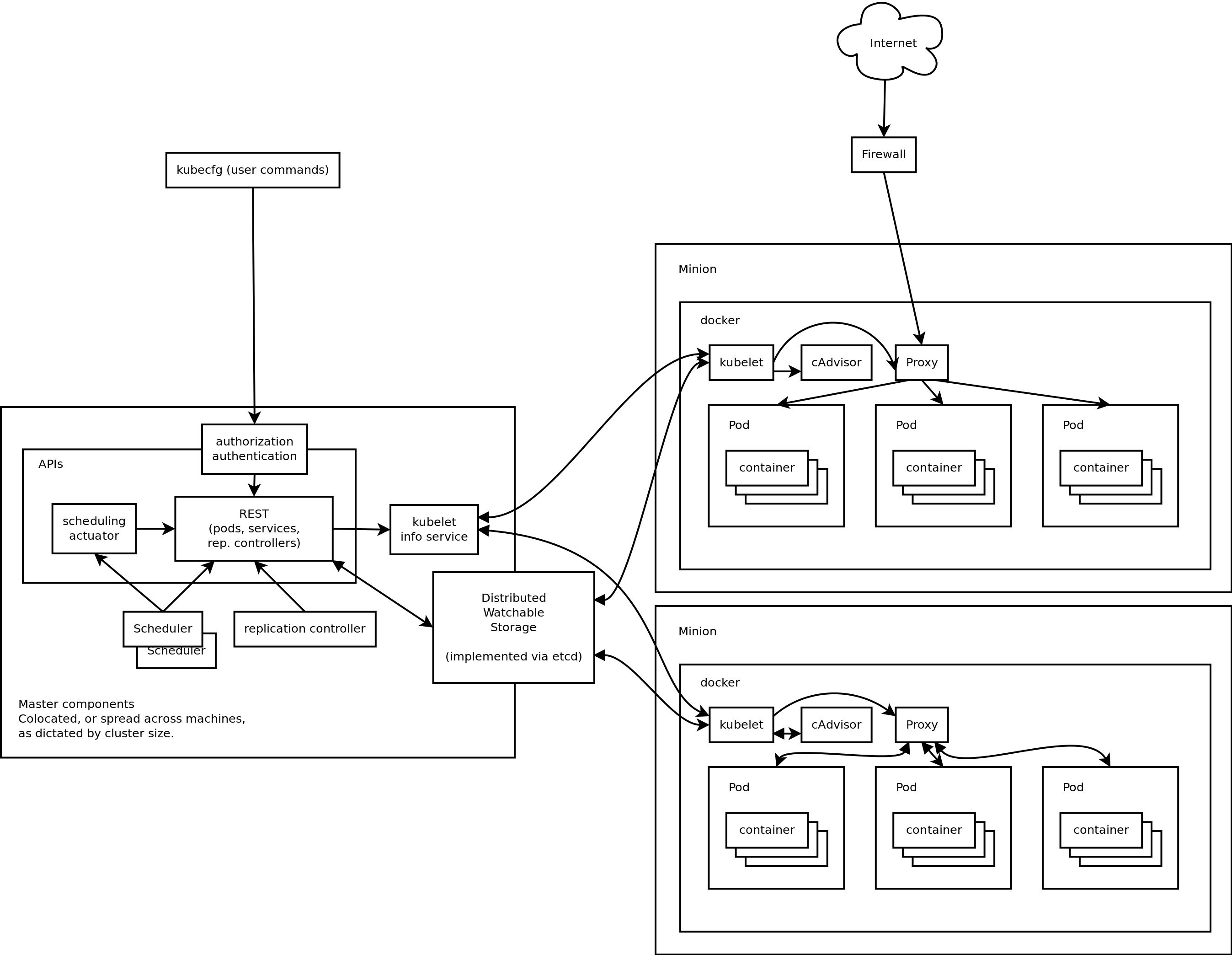
We have been using this great VM management software called Ganeti. It was developed at Google and I love it for the following reasons:
It is at essence a collection of discrete, well-documented, command-line utilities
It manages your VM infrastructure for you, in terms of what VMs to place where
Killer feature: your VMs can all run as network-based RAID1s, the disk is mirrored on two nodes for rapid migration and failover without the need of an expensive, highly-available filer
It is frustrating that relatively few people know about and use Ganeti, especially in the Silicon Valley.
Recently I had an itch to scratch. At the recent Ganeti Conference I heard tell that one could use tags to tell Ganeti to keep instances from running on the same node. This is another excellent feature: if you have two or more web servers, for example, you don’t want them to end up getting migrated to the same hardware.
Unfortunately, the documentation is a little obtuse, so I posted to the ganeti mailing list, and got the clues lined up.
First, you set a cluster exclusion tag, like so:
sudo gnt-cluster add-tags htools:iextags:role
This says “set up an exclusion tag, called role”
Then, when you create your instances, you add, for example: --tags role:prod-www
The instances created with the tag role:prod-www will be segregated onto different hardware nodes.
I did some testing to figure this out. First, as a control, create a bunch of small test instances:
Yes! The first two instances are allocated to different nodes, then when the tag changes to prod-app, ganeti goes back to ganeti06-29 to allocate an instance.
Yesterday we tried out Slack’s new thread feature, and were left scratching our heads over the utility of that. Someone mused that Slack might be running out of features to implement, and I recalled Zawinski’s Law:
Every program attempts to expand until it can read mail. Those programs which cannot so expand are replaced by ones which can.
Eric Raymond comments that while this law goes against the minimalist philosophy of Unix (a set of “small, sharp tools”), it actually addresses the real need of end users to keep together tools for interrelated tasks, even though for a coder implementation of these tools are clearly independent jobs.
Sometimes you’re busy banging out the code, and someone starts rattling on about how if you use multi-threaded COM apartments, your app will be 34% sparklier, and it’s not even that hard, because he’s written a bunch of templates, and all you have to do is multiply-inherit from 17 of his templates, each taking an average of 4 arguments … your eyes are swimming.
And the duct-tape programmer is not afraid to say, “multiple inheritance sucks. Stop it. Just stop.”
You see, everybody else is too afraid of looking stupid … they sheepishly go along with whatever faddish programming craziness has come down from the architecture astronauts who speak at conferences and write books and articles and are so much smarter than us that they don’t realize that the stuff that they’re promoting is too hard for us.
“At the end of the day, ship the fucking thing! It’s great to rewrite your code and make it cleaner and by the third time it’ll actually be pretty. But that’s not the point—you’re not here to write code; you’re here to ship products.”
To the extent that he puts me up on a pedestal for merely being practical, that’s a pretty sad indictment of the state of the industry.
In a lot of the commentary surrounding his article elsewhere, I saw all the usual chestnuts being trotted out by people misunderstanding the context of our discussions: A) the incredible time pressure we were under and B) that it was 1994. People always want to get in fights over the specifics like “what’s wrong with templates?” without realizing the historical context. Guess what, you young punks, templates didn’t work in 1994.
Check if the lid on the computer is open by looking for the word “open” in /proc/acpi/button/lid/LID0/state AND
(… if the lid is open) make a directory with today’s date AND
(… if the directory was made) take a timestamped snapshot from the web cam and put it in that folder.
Breaking it down a bit more:
grep -q means grep “quietly” … we don’t need to print that the lid is open, we care about the return code. Here is an illustration:
$ while true; do grep open /proc/acpi/button/lid/LID0/state ; echo $? ; sleep 1; done
state: open
0
state: open
0
# Lid gets shut
1
1
# Lid gets opened
state: open
0
state: open
0
The $? is the “return code” from the grep command. In shell, zero means true and non-zero means false, that allows us to conveniently construct conditional commands. Like so:
$ while true; do grep -q open /proc/acpi/button/lid/LID0/state && echo "open lid: take a picture" || echo "shut lid: take no picture" ; sleep 1; done
open lid: take a picture
open lid: take a picture
shut lid: take no picture
shut lid: take no picture
open lid: take a picture
open lid: take a picture
There is some juju in making the directory:
mkdir -p /home/djh/Dropbox/webcam/`date +%Y%m%d`
First is the -p flag. That would make every part of the path, if needed (Dropbox .. webcam ..) but it also makes mkdir chill if the directory already exist:
Then there is the backtick substitition. The date command can format output (read man date and man strftime …) You can use the backtick substitution to stuff the output of one command into the input of another command.
$ date +%A
Monday
$ echo "Today is `date +%A`"
Today is Monday
Here is where it gets involved. There are two cameras on this mobile workstation. One is the internal camera, which can do 720 pixels, and there is an external camera, which can do 1080. I want to use the external camera, but there is no consistency for the device name. (The external device is video0 if it is present at boot, else it is video1.)
Unfortunately, fswebcam is a real trooper: if it can not take a picture at 1920×1080, it will take what picture it can and output that. This is why the whole cron entry reads as:
Check if the lid on the computer is open AND
(… if the lid is open) make a directory with today’s date AND
(… if the directory was made) take a timestamped snapshot from web cam 0
Check if the timestamped snapshot is 1920×1080 ELSE
(… if the snapshot is not 1920×1080) take a timestamped snapshot from web cam 1
Sample output from webcam. Happy MLK Day.
Why am I taking these snapshots? I do not really know what I might do with them until I have them. Modern algorithms could analyze “time spent at workstation” and give feedback on posture, maybe identify “mood” and correlate that over time … we’ll see.
Friend: Dang it Apple my iPhone upgrade bricked the phone and I had to reinstall from scratch. This is a _really_ bad user experience.
Me: If you can re-install the software, the phone isn’t actually “bricked” …
Friend: I had to do a factory restore through iTunes.
Me: That’s not bricked that’s just extremely awful software.
(Someone else mentions Windows.)
Me: Never had this problem with an Android device. ;)
Friend: With Android phones you are constantly waiting on the carriers or handset makers for updates.
Me: That is why I buy my phones from Google.
Friend: Pixel looks enticing, I still like iPhone better. I am a firm believer that people stick with what they know, and you are unlikely to sway them if it works for them.
Me: Yeah just because you have to reinstall your whole phone from scratch doesn’t make it a bad experience.
A fleet of TGV waiting to serve passengers in Marseilles, France in 2002. These trains have a top speed of 200 MPH. Proposed US safety rules would permit lighter, faster trains that meet European safety standards to run at speeds of up to 220 MPH.
Current US regulations, from the 1800s and the 1930s, mandate heavier trains to survive crashes. Unfortunately, heavy trains cost more to build, operate, and maintain. Heavier trains are also harder to stop in an emergency.
European train safety regulations are comparable to modern cars: lighter trains are cheaper to build and operate, and they stop faster. They feature “crumple zones” to absorb damage in an accident.
Since the United States is a small market for passenger trains, divergent safety standards make it even more expensive to buy trains. Instead of purchasing inexpensive, reliable, “off-the-shelf” European-designed train sets, vendors need to make alternate, heavier, slower, more expensive designs for American railroads. The adoption of European safety standards will make it cheaper and easier for American railroads to provide modern, comfortable, faster passenger service.
In anticipation of these new rules, Amtrak in September announced the purchase of 28 Avelia Liberty trains from the French company Alstom. The trains will be manufactured in upstate New York and will be used for Acela service starting is 2021. These trains can be upgraded to run at 220 MPH, but this will only be allowed after right-of-way upgrades on the Northeast Corridor.
These rules coming at the end of the Obama administration, with promises of infrastructure spending under the Trump administration, could help American rail transport see more rapid improvements in short order.
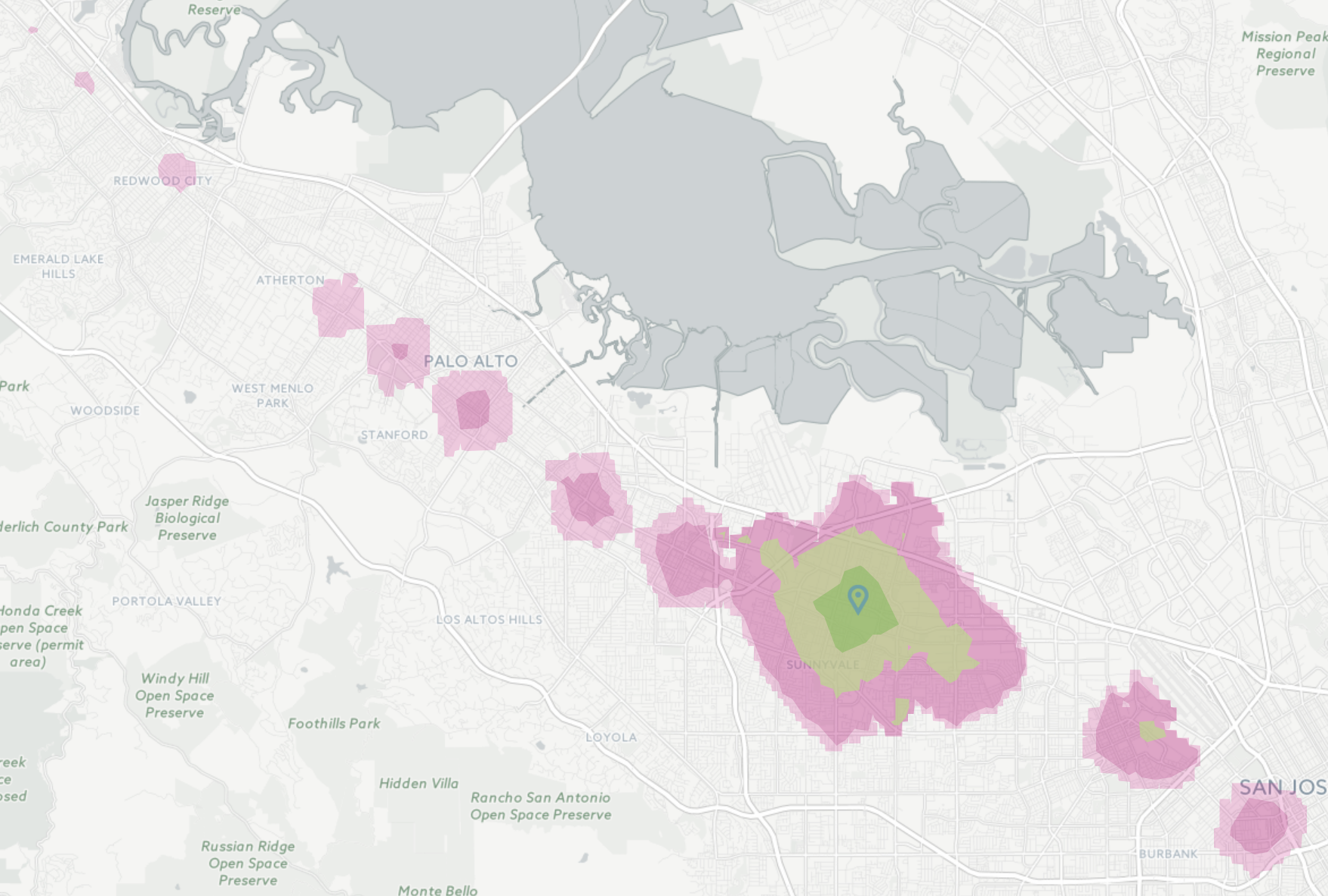
Via Steve Vance, Mapzen has a new tool, Mobility Explorer, which can generate isochrones for walking, biking, driving, and transit. I have previously used tools provided by Walk Score, but Mapzen seems more accurate, and the transit shed can be calculated based on a time-of-day.
Here is how far you can get on public transit from Sunnyvale at noon on a Wednesday in 15, 30, 45 and 60 minutes.
The colors on the web site color scheme are not that great. On Steve’s blog you can see he’s generated his own map via an API call.
I was in Chicago this week. There was a death in the family, so it was good to be among my kinfolk with our adorable, loving child.
Chicago is famously corrupt and moribund and the State of Illinois is mired in perpetual scandal. It is a magnet for immigrants but it is also a city from which many of us Californians are originally from. I’ve gotten used to the California way and I generally prefer it but what I noticed this week in Chicago was all the construction.
For a city that is corrupt and moribund, there was an awful lot of demolition and rebuilding going on. On the way to the L in the evening we stopped and stared over a fence as a variety of heavy machines worked under brilliant stadium lights. The star of the show was a yellow machine with a huge claw on the end of a boom arm reaching several stories up, to the top of a building, it was tearing down from the top, girder by girder, as another machine sprayed down the dust with a water hose. The claw was at the very end of its reach, it felt the machine was on tippy toes, as it tugged away, girder after girder, waiting for torrents of debris to fall, pulling the pieces out and dropping them into piles to be dragged into more discrete piles by lesser enormous machines. It was like watching dinosaurs go about their business. Father, Son, and Grandmother: none of us could take our eyes off the marvel. “They should sell beer and peanuts,” said I.
The neighbors of this derelict house in Sunnyvale are terrified at the prospect of it being replaced with housing for families.
We don’t get this in Suburban California. What little “history” we have is viciously guarded and any attempt to replace the old with newer and better is often met with resistance and exaggerated speculation as to the intentions and end results of new development. You don’t see that so much in the old country–In Chicago, and in any place with some history under its belt, everyone knows that they are surrounded by at least a century of continuity–Everyone is merely links in a great chain. The city is inherited and bequeathed and the hope is to leave it in a little better shape: Urbs in Horto.
In Dublin, I saw them building a light rail line, right down an ancient street. It made the Northern Californian in me jealous.
They say that University Politics is the most vicious because the stakes are so low. I get a sense of that observing some of the political rhetoric in Sunnyvale. Out here the city is so new and raw that the idea of changing it implies that those who built the city and have lived in it until now are being completely rejected by the hordes of newcomers flooding the city from the Midwest and the Far East. But in the ancient lands where the immigrants come from, there is no such sentiment: the cities are naturally timeworn, and the idea of redevelopment is an intuitive component of the cycle of death and rebirth.
Fierce as a dog with tongue lapping for action, cunning as a savage pitted against the wilderness,
Bareheaded,
Shoveling,
Wrecking,
Planning,
Building, breaking, rebuilding,
Under the smoke, dust all over his mouth, laughing with white teeth,
Under the terrible burden of destiny laughing as a young man laughs,
Laughing even as an ignorant fighter laughs who has never lost a battle
The land in which I live would be enriched if it embraced a bit of the poetry of the land in which I was born.
There’s a darkness upon me that’s flooded in light
In the fine print they tell me what’s wrong and what’s right
And it comes in black and it comes in white
And I’m frightened by those that don’t see it
When nothing is owed or deserved or expected
And your life doesn’t change by the man that’s elected
If you’re loved by someone, you’re never rejected
Decide what to be and go be it




{kind=link}