On October 10, 2016, file 16-0548 was heard by the Sunnyvale Planning Commission. The item was to down-zone a condominium development per the General Plan, and to up-zone a one third acre parcel from Residential Low Density to Residential Low-Medium Density. By up-zoning the site at 838 Azure St, the property owner would be able to build four homes on the property instead of a maximum of two.
The Planning Commission passed the down-zoning proposal but denied the up-zoning at 838 Azure St. I do not believe the decision with regard to 838 Azure was consistent with the public interest of Sunnyvale residents. At a time of housing crisis, we should err on the side of providing more affordable homes for more families, and the location at 838 Azure is well suited to providing housing with minimal impact on congestion.
Current Status and Options
The property presently hosts two dilapidated structures which had recently housed squatters. There are dying trees and contaminated soil from Sunnyvale’s orchard days.
Proposed zoning for 838 Azure St
Present zoning is R0: 7 homes per acre, or 2 per 1/3 acre
Two lots of 7,200 square feet, homes up to 3,240 square feet
Requested zoning is R2: 12 homes per acre, or 4 per 1/3 acre
Four lots of 3,600 square feet, homes up to 1,620 square feet
Affordability
Status Quo
Change Zoning
House Type
Single Family
Townhome
House Size
3200 sq ft / 5 bed / 3.5 bath
1600 sq ft / 3 bed / 2.5 bath
Home Price
$2,400,000
$1,000,000
Monthly Cost
$12,000
$5,000
Household Income
$436,000
$182,000
Families Housed
2
4
The lot in question is about 14,400 square feet, and present zoning allows for up to two houses. At 45% FAR one can build two homes of 3,200 square feet. Comparable homes in the area are typically 5 bedroom, 3.5 baths at $2,400,000. With a 20% down payment of $480,000, a 30 year fixed mortgage at 3.875% with taxes and insurance runs nearly $12,000/mo.
On the other hand, a 1,600 square foot townhouse or condo in this area is typically 3 bedroom, 2.5 bath at $1,000,000. With a 20% down payment, a 30 year fixed mortgage, taxes, insurance runs nearly $5,000/mo.
If we assume that housing is “affordable” at 33% of Gross Income, then the big houses are affordable to a family with $436,000 annual income, and the smaller homes are affordable at $182,000.
Location: Pedestrian and Transit Quality vs Congestion
Much of Sunnyvale is poorly suited to walking or public transportation. Housing in such areas encourages automobile trips and results in congestion. If you want to increase housing while avoiding congestion, you want to place the housing in areas where walking and public transit are viable options: when people have the option not to drive they are less likely to add congestion.
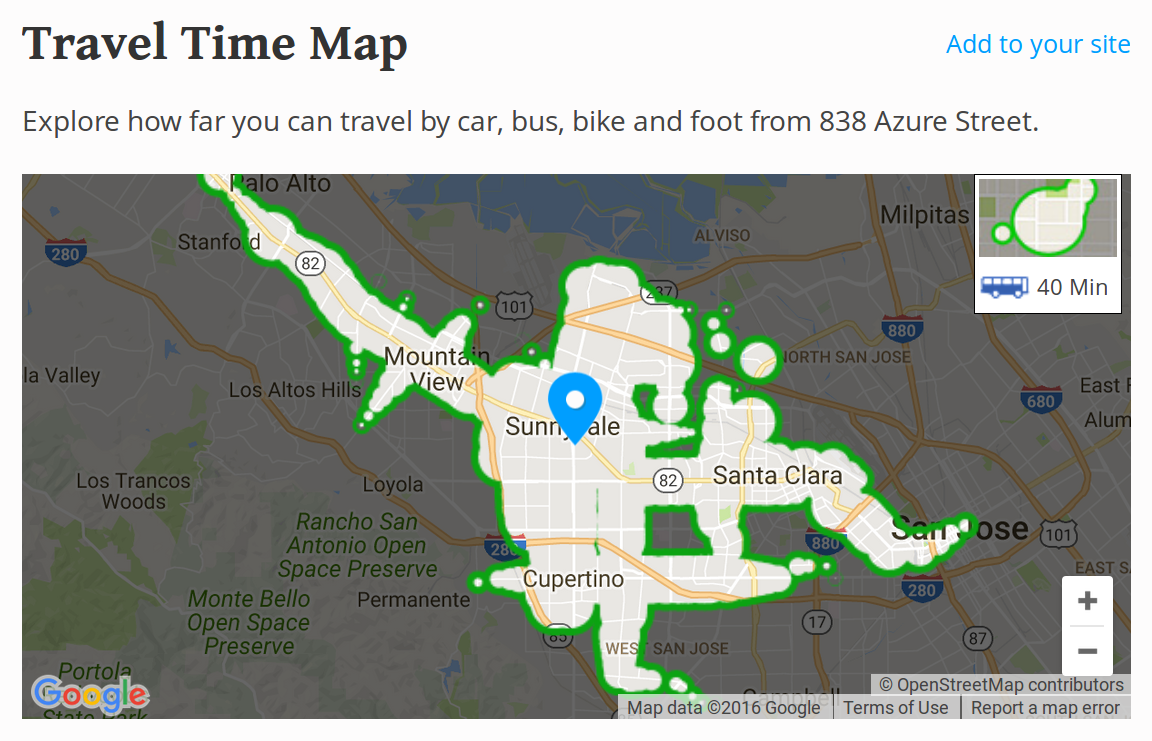
The average Walk Score in Sunnyvale is 55. For 838 Azure the walk score is 78. The site is well within Sunnyvale’s walkable downtown core, a very close walk to multiple groceries, restaurants, and Murphy St. This pedestrian accessibility does not encourage automobile trips, thus it mitigates congestion.
To avoid congestion, put housing in Sunnyvale’s walkable core: 838 Azure is at the Y of Mathilda and Sunnyvale in the lower right. Source: Sunnyvale Walk Score
The site is very near VTA’s premier bus route: the 22/522 El Camino Real, as well as the 55 and 54 routes for North-South mobility. Within an hour, public transit can get residents across Sunnyvale, including the offices on the North Side, as well as much of Cupertino and Santa Clara. The downtown areas of San Jose, Mountain View, and Palo Alto are accessible. At just over a mile to Sunnyvale Station, the site is not a convenient walk to Caltrain: residents may prefer to bicycle.
Via Walk Score: where you can get from 838 Azure via public transit.
Public Comment and Planning Board
Two neighbors spoke against the zoning change. A neighbor who lived in an adjacent townhouse was concerned that the development of townhouses on the neighboring property would not meet his aesthetic standards. A neighbor to the south was concerned that his dogs might get out if the property was developed, and that if the driveway were moved from Sunnyvale-Saratoga to Azure then there would be less street parking available on Azure.
Per the minutes:
Commissioner Melton noted that the benefits of the GPA and Rezone of the Azure site are the PD designation and an increase in housing density, and that the negatives include parking, neighborhood incompatibility and inappropriate density.
Commissioner Simons said he does not like the potential spot zoning of 838 Azure.
…
MOTION: Commissioner Melton moved and Commissioner Simons seconded the motion to recommend that City Council deny the General Plan Amendment and Rezone for 838 Azure Street.
Vice Chair Rheaume said he is not supporting this motion and supports increasing the density of this lot.
This item should come before the City Council on November 1. Anyone who might wish to speak up on behalf of the virtue of increased housing in Sunnyvale can contact the City Council or make a public comment of up to three minutes at the upcoming council meeting. I am hoping to attend and speak November 1. If you think you might also be interested, or would like to be notified of any updates, please drop me a line: dannyman@toldme.com.
Postscript
This item was considered by the Sunnyvale City Council on November 1, 2016. City Council heard testimony from City Staff and the Property Owner. City Council candidate John Cordes and I made public comments in favor of the change. A few neighbors made public comments against the change.
The City Council enacted an ordinance to change the zoning at 838 Azure from R0 to R2-PD. The vote was 6-1, with Council Member Pat Meyering in dissent. Council made it clear that they were only approving the zoning change, in order to provide more housing in an area well-suited to pedestrian, bicycle and public transit. Council was generally most concerned with how the development would transition from the adjacent R2 zones to the rest of the neighborhood, which is among the several considerations which will be addressed subsequently in the planning process.
The Property Owner is now at liberty to submit plans for development, which will be subject to review by the Zoning Administrator, with community feedback, and potentially by the Planning Commission and the City Council.
Caveat:it has been pointed out to me that my data source is not entirely accurate.Raw data can be obtained directly from the city. Unfortunately, that data is provided in PDF format. If I find a convenient way to parse the data out of those PDF files, I’ll take a crack a re-doing the Financial Backings visualization, below.
Heading up the “Core” are Mayor Glenn Hendricks and Vice Mayor Gustav Larsson, who have each received overwhelmingly large sums from the National Association of Realtors Fund.
Jim Griffith is an Software Engineer who has mainly bankrolled his own campaigns. He is the only second-term member of the council, thus his cumulative financial backing is larger than most members of the council, with the exception of Mayor Hendricks and Vice Mayor Larsson. Jim maintains a blog about city council activities at dweeb.org.
Next are what I would label the “Friends” which includes Larry Klein and Tara Martin-Milius. Klein very recently won a special election held in August after the resignation of Dave Whittum. Neither of these candidates have the volume of donations as Hendricks, Larsson or Griffith, but the Inner Core have made friendly contributions to the Friends. Martin-Milius has received contributions from Hendricks, Larsson, and Griffith while Klein has received contributions from Hendricks and Griffith.
The Inner Core and Friends make up a five-member majority. Council motions are often made and carried with minimal dissent.
Beyond the Core are the two “Independents.” Jim Davis‘ campaign contributions are mainly from non-resident individuals, none from the Core members. He generally votes along with the Core, though he did vote against the Maude Ave bike lane, an issue which I took a special interest in. Pat Meyering‘s campaign is completely self-funded. He often clashes with Mayor Hendricks and other members of the council.
Mapping Out the Election
The Deep Pockets (Hendricks, Larsson, Griffith) are not up for election this year, but everyone else is.
Seat 4: Recently won by Larry Klein, is challenged by John Cordes and Mike McCarthy. Klein, who recently served on the Planning Commission, is backed by a few Business and Real Estate PACS, and several residents, including the Core council members, and Stephen Williams, who ran against him in the special election. John Cordes, who also ran against Klein in the special election, is an environmentalist who serves on the Bicycle and Pedestrian Advisory Commission. He is mainly self-funded, with an even split between resident and non-resident contributions, and a single PAC donation from the California League of Conservation Voters. Mike McCarthy is entirely self-funded.
Seat 5: Incumbent Pat Meyering is solely self-funded, and I could not find a campaign web site. He is challenged by Russell Melton, who has served several terms on the Planning Commission, and has the support of several developers, the Core council members, and numerous individuals. Melton also managed Mayor Hendricks’ successful 2013 City Council campaign.
Seat 6: Incumbent Jim Davis is a former Public Safety Officer who has served many government and community organizations. He is funded mainly by non-resident individuals. Challenger Nancy Smith has chaired the Santa Clara County Water District Environmental and Water Resources Committee, and is funded by several residents and non-residents.
Seat 7: Incumbent Tara Martin-Milius is funded in the main by several individuals, including Core council members, along with business and real estate contributions. She is challenged by unfunded Ron Banks and self-fundedMichael Goldman.
Visualizing the Council and the Election
In an attempt at objectivity, I have compiled the following table to provide a quick reference to in understanding the Council and the election. I welcome feedback, especially factual corrections.
█ Business █ Business PAC █ Developer █ Real Estate PAC █ Candidate █ Elected Official PAC █ Political Party █ Political Committee █ Resident █ Non-Resident █ Environmental PAC █ Social Issues PAC █ Union PAC Source: http://www.specialinterestwatch.org/, cumulative contributions through June 30, 2016
In the sky, we could sea the Earth. Where were we? Someone explained that this was a rare astronomical phenomenon where the moon reflected the Earth’s image back onto itself. We stood, looking up in awe. I snapped a picture on my smart phone. The apparition slid across the sky toward the horizon. We were on a cruise ship, approaching a large orb, a micro-planet of waves crashing upon each other. A label hovered just in front of the microplanet: bold block small-caps serif letters in white read:
Mauna Kea
I was overcome with religious ecstasy. I fell to my knees and bowed my head and allowed the emotion to sweep over me. Then I took a peek around and noticed everyone else was nonchalant.
A rant posted on a colleague’s Facebook wall in reaction to the New York Times:
I read The New Yorker too much when I had free time and the gist of it was: Earth’s climate is usually pretty erratic, but after the last ice age, about 10,000 years ago, the climate entered an unusually stable phase. At that point, our species, after 200,000 years, for some reason, mastered agriculture and civilization, and that civilization has disrupted this stable phase and we are moving back into unstable climate patterns. Whether the world civilization can continue without the original agricultural lynch pin of a stable climate is a question which will be answered within our lifetimes.
Earth’s Average temperature. Our species emerged around the 200 mark, agriculture and civilization start at around 11 where you see that flat red line, which ends .. now. CC: Glen Fergus
I had mixed feeling watching the Democratic National Convention because on the one hand they acknowledge that Climate Change is a Real Thing and we Ought to Do Something but then they kept reassuring us that it was just one of those kind of good things to do for future generations and not actually some kind of imminent shitfest that is going to be a bigger and bigger problem every year for the forseeable future, not to mention that we’ve already pretty much screwed the pooch anyway by ignoring the issue so we get to deal with it anyway but will still need to address climate emissions to keep it from going from pretty awful to worst case scenario.
Flash Flood in Australia CC: Nick Carson It starts with floods and droughts, then crop failures, famine, mass migration, political turmoil, fascism … talking about sea level is burying the lead.
And like what that means is maybe or maybe not the Democrats have their hearts in the right place but the messaging is just as focus-grouped and they’re nearly as averse to disturbing the status quo. “Okay, so, your likely voters believe climate change is a big deal, but most of them would be reluctant to do anything about it, so you’ve got to acknowledge the problem without making anyone feel threatened.” And over on the right its like “Well, Climate Denial excites the base of excitable racist lunatics AND it pretty much guarantees PAC money from the oil companies so any time they ask you say that yeah, there is a climate change but that is in Jesus’ hands.”
See Also: http://xkcd.com/1732/ — a cartoon illustrating human history versus the temperature record depicted in the final panel.
Upon my return to work this week, one question was on the tongues of polite colleagues: “how was Alaska?” I start to explain that I didn’t experience much of Alaska because I spent the week on a cruise ship, which involved a fair bit of eating, drinking, reading, taking pictures, and trying to keep Tommy amused. I don’t trouble these nice people with too much detail. After all, there is now a blog post for those who care to know too much. Welcome to the verbose answer.
Part I: Cruise Ship Life
This is what Alaska looks like from a cruise ship.
Last week the family went on a cruise aboard Holland America’s MS Westerdam. The ship went from Seattle up the coast of Alaska and back. From that vantage, Alaska is days and days of unpopulated, beautiful vistas, floating by as you dine on an endless buffet, and catch up on reading as friendly Indonesians bring reasonably-priced drinks. The ship has something like twenty bars, a casino, a jewelry store, an “art gallery” and a modest library with absolutely no books about modern cruise ships, but various board games with missing pieces. This idyll is punctuated every day or two by our collective descent, like a plague of locusts, onto remote little towns who have decided to augment their fishing and lumber industries with tourist entrapment. “Diamonds Cheaper than on the Ship” touted several stores adjacent to the port in Juneau.
“I don’t know why Juneau has so many diamond shops,” said our driver. “Diamond isn’t even our state gem stone. You know what that is? Jade! Now if you look out to our right as we go over this bridge, you’ll see a bald eagle …” We were riding a bus out to a shore excursion where we got to ride a wheeled cart pulled by sled dogs. This was fun: you get about six tourists on a cart and a dozen or more eager dogs pull us around some roads on a loop in the woods for not more than a mile. Our musher was a guy from Michigan who explained that the hardest part of the year is driving his dogs up from Michigan, but now that tourists would pay to ride the cart the mushers could just stay up North for the Summer. His concern is that the dogs do best around -20F, so when they pull tourists around on wheeled sleds at 50F he wants to make sure they don’t work too hard and keep hydrated.
I spent a lot of my time keeping Tommy entertained. As a lady explained to the grownups about sled dogs and the annual races we got to pet a friendly dog and wander over by the musher’s camp. When the lecture was done the puppies were brought out and fondled. After the hot chocolate we got on the bus back to port. “If you look out on our left you’ll see that same eagle in the same spot.” It turns out that bald eagles spend a lot of time sitting up high enjoying the scenery and contemplating their next meal. As a cruise ship passenger, I felt I could relate.
Homo sapiens caring for its young on a cruise ship off the coast of Alaska.
Part II: Glacier Bay
The high point of the cruise, in my opinion, is when the ship sails up glacier Bay and spends an hour or so floating in front of a giant glacier:
The passengers took turns meandering on to the front deck to take pictures. Even Tommy wanted a cut of the action.
Tommy takes a picture of the glacier. Camera and wardrobe supplied by Mom.
As we floated away from the glacier I caught some of a talk from a Park Ranger about how 300 years ago Glacier Bay was more of a Glacier Valley populated by Tlingit people. But then the Little Ice Age caused havoc world wide, and the Tlingit recorded that the glacier came down through the valley at the speed of a running dog. The people ran to their canoes and evacuated. Eventually, the glacier reached the ocean. Upon contact with salt water the glacier then dried back up the valley, scraping away the ground and all evidence of Tlingit habitation, leaving what we now call Glacier Bay.
Enter John Muir. You have probably heard of him. His interest in Yosemite led him to Glacier Bay, on the idea that Yosemite may have been carved by glaciers, so he should go and study them. It was some rough adventure, and the Park Ranger digressed into a tale of how one day John went out to check out the glaciers, alone, except for one weird little dog who insisted on following him. The day consisted of a lot of jumping across crevasses and the dog kept up, until on the way home, as it was getting dark and cold, there was a crevasse that was too wide for either to jump, but there was a narrow ice bridge about ten feet down. John pulled out his axes and made it down one side, scooted across the ice bridge, and pulled himself up the far side, and looked back at the dog.
The dog looked at John, looked at the crevasse, and then began wailing. John persuaded the dog to calm down, then patiently explained that he had to try the crossing, as the only way to make it across was to try, and that if he failed to make it across that at least his bones would have a nice resting place. The dog thought it over, managed to climb down and across the ice bridge and back up to John, and they were then such BFFs that John published a book.
“Hush your fears, my boy, we will get across safe, though it is not going to be easy. No right way is easy in this rough world. We must risk our lives to save them. At the worst we can only slip, and then how grand a grave we will have, and by and by our nice bones will do good in the terminal moraine.”
–John Muir to Stickeen
It came to pass that Glacier Bay came under the protection of the federal government, which was well and good until the Tlingit came to note that it was an ancestral homeland, and the administrators of the time didn’t know what to make of that. So, after the Park Ranger spoke, a Tlingit woman came on stage to tell her own story.
The story began with an introduction to Tlingit culture. They identify by moiety, clan, and tribe. The moiety is interesting because you are either Raven or Eagle, you inherit your moiety from your mother, and you are required to marry a person of the opposite moiety. I haven’t done the logic here but it is understood to function as a system to limit in-breeding, which is a valid concern for a tribal people living at the edge of the Earth.
Anyway, her real story was of the time of forced assimilation. Her Grandmother died young, so on the pretext that a father can not raise his own children, at the age of six she and her siblings were relocated and scattered to live with families across the continental United States and thereby leave their barbarian ways behind them and become modern civilized folk. At the age of eighteen the lady’s mother returned to Alaska, where she knew nobody. She found a job and in time a nice fellow courted her, but she did not wish to marry because she did not know where she came from, or what her clan was. They conferred with elders who viewed the union as acceptable and they adopted her into a clan. In time, she learned of her birth clan, and that is how the woman speaking to us explained that due to her mother’s story, she identified with two clans.
The story gets happier with time. The woman married a Czech and has a multilingual daughter. The daughter lives in Washington but is learning Tlingit now from the University of Alaska … via Skype! And now the government has seen to the erection of a Tlingit Tribal House, which actually just opened on Thursday, August 25, 2016.
Part III: Sitka
Sitka is an island with no road connection. You arrive and depart by water or by air. Our modern cruise ship pulled up to a wooden dock on a gravel lot with piles of shipping containers. We walked on up to a little gift shop from which a fleet of buses ferried us into the city center. Our bus driver was apologetic that he didn’t know much to say about Sitka as he had been flown in from Juneau just the night before, owing to a local shortage of bus drivers, but he shared a factoid or two he had had a chance to pick up from Wikipedia. Once we got to town we had 45 minutes until another bus would whisk us on a tour to see raptors, salmon, and bears. (Oh my…) Adjacent to the bus terminal was the public library where Tommy made friends in the children’s area while his parents availed themselves of free wifi.
Oh, you were wondering: the ship has some slow, expensive wifi which we did not use except to look at the New York Times which sponsors the ship library and is therefor the only “free” site on the ship’s wifi. I don’t know if this is by design or by an oversight of the firewall configuration, but there’s no “ten article per month” limit. This is more Internet then you really need for a week at sea. More Internet that you really need on land, in all honesty. The ship is also equipped with a mobile device tower, but as with every town we stopped at in Alaska, there was no free roaming for T-Mobile.
I had to carry Tommy out of the auditorium because he was getting excited and we had been cautioned not to freak out this magnificent bald eagle, which Mommy photographed.
The Raptor Center is for rehabilitation of injured raptors, particularly bald eagles. Behind the raptor center was a nice trail with bear poop on it. It led to a stream where we figured out that dark spot in the water was a huge mass of salmon. It was all very pleasant but our time was up and we walked back up the trail, one eye out for bears, then we were off to …
… the Fortress of the Bear! Which is a refuge for orphaned bears, situated in what look to me like retired water clarifiers. Groovy stuff.
Finally, to the Sitka Science Center, where they study the life cycle of salmon and run a small hatchery operation. Since messing up the ecosystem mid-way through the last century, the state has since developed a system of hatcheries which annually release something like a billion fry a year, so there will always be plenty of tasty fish to eat. Adjacent to the center was a stream fairly choked with salmon who were returning to spawn. Someone asked if they were good eating, and the kid giving the tour explained that no, the flesh of the fish swimming upstream was already decomposing as at this point all metabolic energy they have is dedicated to the mission of spawning. The fish could still be used for animal feed and the like but no, you wouldn’t want to eat them.
Part IV: Ketchikan
A view from our cruise ship of three more cruise ships and the ever-present tourist trap fixture: a diamond store.
Daddy managed to send some postcards.
Tommy acquired a bag of blue kettle corn.
Mommy acquired some souvenirs and saw some salmon.
After the rigors of Ketchikan, Tommy is spent.
Part V: Cruise Ship Operations
I signed up for a tour of ship operations. Thanks in part to the fiber content of swiss-style muesli and a devotion to coffee, I had to excuse myself mid-way through the early-morning bridge tour, but the “hotel operations” portion of the tour was sufficiently fascinating. I was able to fill in the gap from my “bridge tour” by attending a separate talk from the Captain. If you really want to see the bridge and engines, this guy has you covered.
The ship is basically a collection of massive diesel generators. They burn a cleaner gas near shore and cheaper bunker oil at sea. The generators supply electricity to the guest facilities, the galley, and finally, to the ship’s engines, which consist of a pair of azipods mounted on both sides of the bottom rear of the ship. The azipods can rotate 160 degrees each, which combined with a set of bow thrusters, give the captain plenty of ability to park a ginormous cruise ship at little Alaskan ports. The captain noted that at 11pm when the galley shuts down, the power available for the engines goes up, and the speed ticks up a notch.
We started at the galley, which is massive. There are a handful of restaurants on the ship, and the food is all prepared in the galley, which is strategically located for quick service. If you’ve seen an industrial-sized kitchen before, then you know what’s up.
The galley. Huge. Stainless. Spotless.
Next, the bakery, which is compact, maybe the size of a two-car garage, yet still supplies the entire ship with fresh pastries throughout the week. We saw the alcohol storage room, and so of course mimosas were served.
Drinking alcohol is a favorite activity on board cruise ships.
We saw dry stores–they pointed out “the most important fuel on the ship”–a pallet of rice.
The Indonesian and Philippine crew collectively consume 500 lbs a day of rice. Any less would assure mutiny.
There is a small refrigerated room labeled “Coffin Store” which it turns out normally stores flowers–the ship has two florists–but should any of the thousands of people on board the ship expire prematurely, flowers are removed from the Coffin Store until there is enough room for the newly deceased. If the dead are capable of appreciating anything, I like to think they share my admiration and respect for the elegant efficiency of keeping the Coffin Store pre-loaded with flowers.
B Deck is under water, so you’ll see waterproof doors, and you can tell you are on a ship. You see nothing like this in guest areas.
After stores, we saw the waste management section. The ship generates an amount of waste comparable to a small city, with less room to store it. Everything that can be recycled is separated, shredded, compacted, sealed, stowed, and then sold at port when possible. Retired linens are converted into rags for cleaning the engines, and the oily rags from cleaning the engines are sealed into casks which I assume are disposed of properly. Organic (food) waste, at a rate of 3 cubic meters per day, is released into the ocean at night while the ship is chugging along. The organic waste is released in 1cm cubes so as not to attract seagulls into forming an entourage behind the aft staterooms.
During the Bridge Tour the Captain noted that waste water from the toilets is used for ballast. This makes the “wet sewage wastes” cask all the more mysterious.
There’s a mess for ship’s crew and another, larger, more aesthetically appealing mess for the Indonesian and Philippine crew, where the bulk of the ship’s rice is consumed. We had to wait until Friday prayers were completed before we could see the latter mess area, which makes an attempt to remind folks who are at sea serving well-off Americans of the life and vibrant color of their home land. Whether the canteen decor does anything for morale I do not know, but I reckon the ritual use of a clean laundry bin filled with prayer rugs helps more than a few lonely souls keep their spirits up.
The mess hall decor tries to remind the staff of home.
Later in the tour we breached American etiquette to learn a bit about the salary on board ship. One assumes the money is good enough to convince folks to leave home, typically for ten months at a time. We were informed that stateroom attendants, after tips, can take home $1,500-$1,800/mo. It was noted that stateroom attendants make considerably better money than other staff, especially compared to, say, a porter, whose job is mainly to carry stuff around.
Checking up on the Internet, the average salary in Indonesia is about $1,200, and the median is about $750. Kitchen Staff average $90/mo, and a Waiter $300/mo. A Call Center job around $700/mo. The World Bank ranks Indonesia as “lower middle income” … I’m not sure I will ever have gotten my head and my heart around the disparities of our world. I reckon it is better that I never do.
We visited the ship tailors, whose main occupation is in keeping the staff properly attired. The hotel laundry has a lot of busy men and machines: washers, dryers, hospital-grade sanitizers, automated presses for pants and for suits. The dry cleaning is … look, in all honestly the wonders of the laundry were pretty much lost on me, save for the existence of a $400,000 machine about the size of our living room that folds sheets. There is a separate laundromat on the ship for the staff to do their own laundry at no charge.
Part VI: Victoria
The night before our return to Seattle was a stop in Victoria, Canada. Before our arrival the captain made a ship-wide, long-winded announcement in his thick Dutch accent, explaining that overnight, they had a problem with one of the azipods, so they had to stop it, turn the ship around, turn the azipod back on, then resume course. But they hadn’t been able to make up the time so we would arrive in Victoria about 45 minutes late, and this is why he was deeply apologetic to those whose shore excursions would consequently be rescheduled or canceled outright.
Nobody cared to see our passports. I grabbed some Canadian cash and we rode a double-decker bus into town, which resembled France. As it was around his bed time, Tommy fell asleep on my shoulder and I got to carry him around town. We bought some chocolates and I took a seat near one of the buskers down at the waterfront while Mommy took some pictures. We later strolled around the kiosks at the waterfront and Tommy managed to awake in time to catch site of a food truck containing an industrial robot serving ice cream. If there is one thing every parent knows about Canada it is that children are entitled to any robot-dispensed soft-serve ice cream that they can spot.
At one point the robot encountered some imperceptible difficulty, and three humans instantly appeared to render technical support. Among other things someone had to fiddle with the robot’s computer, which is a Japanese version of Windows XP.
We took a taxi back to the ship. Nobody cared to see our passports.
I’ve been a SysAdmin for … since the last millennium. Long enough to see certain fads come and go and come again. There was a time when folks got keen on the advantages of chroot jails, but that time faded, then resurged in the form of containers! All the rage!
My own bias is that bare metal systems and VMs are what I am used to: a Unix SysAdmin knows how to manage systems! The advantages and desire for more contained environments seems to better suit certain types of programmers, and I suspect that the desire for chroot-jail-virtualenv-containers may be a reflection of programming trends.
On the one hand, you’ve got say C and Java … write, compile, deploy. You can statically link C code and put your Java all in a big jar, and then to run it on a server you’ll need say a particular kernel version, or a particular version of Java, and some light scaffolding to configure, start/stop and log. You can just write up a little README and hand that stuff off to the Ops team and they’ll figure out the mysterious stuff like chmod and the production database password. (And the load balancer config..eek!)
On the other hand, if you’re hacking away in an interpreted language: say Python or R, you’ve got a growing wad of dependencies, and eventually you’ll get to a point where you need the older version of one dependency and a bleeding-edge version of another and keeping track of those dependencies and convincing the OS to furnish them all for you … what comes in handy is if you can just wad up a giant tarball of all your stuff and run it in a little “isolated” environment. You don’t really want to get Ops involved because they may laugh at you or run in terror … instead you can just shove the whole thing in a container, run that thing in the cloud, and now without even ever having to understand esoteric stuff like chmod you are now DevOps!
(Woah: Job Security!!)
From my perspective, containers start as a way to deploy software. Nowadays there’s a bunch of scaffolding for containers to be a way to deploy and manage a service stack. I haven’t dealt with either case, and my incumbent philosophy tends to be “well, we already have these other tools” …
Container Architecture is basically just Legos mixed with Minecraft (CC: Wikipedia)
Anyway, as a Service Provider (… I know “DevOps” is meant to get away from that ugly idea that Ops is a service provider …) I figure if containers help us ship the code, we’ll get us some containers, and if we want orchestration capabilities … well, we have what we have now and we can look at bringing up other new stuff if it will serve us better.
ASIDE: One thing that has put me off containers thus far is not so much that they’re reinventing the wheel, so much that I went to a DevOps conference a few years back and it seemed every single talk was about how we have been delivered from the evil sinful ways of physical computers and VMs and the tyranny of package managers and chmod and load balancers and we have found the Good News that we can build this stuff all over in a new image and it will be called Docker or Mesos or Kubernetes but careful the API changed in the last version but have you heard we have a thing called etcd which is a special thing to manage your config files because nobody has ever figured out an effective way to … honestly I don’t know for etcd one way or another: it was just the glazed, fervent stare in the eyes of the guy who was explaining to me the virtues of etcd …
It turns out it is not just me who is a curmudgeonly contrarian: a lot of people are freaked out by the True Believers. But that needn’t keep us from deploying useful tools, and my colleague reports that Kubernetes for containers seems awfully similar to the Ganeti we are already running for VMs, so let us bootstrap some infrastructure and provide some potentially useful services to the development team, shall we?
I recently started using sslmate to manage SSL certificates. SSL is one of those complicated things you deal with rarely so it has historically been a pain in the neck.
But sslmate makes it all easy … you install the sslmate command and can generate, sign, and install certificates from the command-line. You then have to check your email when getting a signed cert to verify … and you’re good.
The certificates auto-renew annually, assuming you click the email. I did this for an important cert yesterday. Another thing you do (sslmate walks you through all these details) is set up a cron.
This morning at 6:25am the cron got run on our servers … with minimal intervention (I had to click a confirmation link on an email yesterday) our web servers are now running on renewed certs …. one less pain in the neck.
So … next time you have to deal with SSL I would say “go to sslmate.com and follow the instructions and you’ll be in a happy place.”
A moment of thought and I realized the challenge was easy, and heartening. This speech has been given before:
“Hillary Clinton understands that we must fix an economy in America that is rigged and that sends almost all new wealth and income to the top one percent. Hillary Clinton understands that if someone in America works 40 hours a week, that person should not be living in poverty.
She believes that we should raise the minimum wage to a living wage. And she wants to create millions of new jobs by rebuilding our crumbling infrastructure. – our roads, bridges, water systems and wastewater plants.
This election is about which candidate will nominate Supreme Court justices who are prepared to overturn the disastrous Citizens United decision which allows billionaires to buy elections and undermine our democracy; about who will appoint new justices on the Supreme Court who will defend a woman’s right to choose, the rights of the LGBT community, workers’ rights, the needs of minorities and immigrants, and the government’s ability to protect the environment.
This campaign is about moving the United States toward universal health care and reducing the number of people who are uninsured or under-insured. Hillary Clinton wants to see that all Americans have the right to choose a public option in their health care exchange, which will lower the cost of health care.
She also believes that anyone 55 years or older should be able to opt in to Medicare and she wants to see millions more Americans gain access to primary health care, dental care, mental health counseling and low-cost prescription drugs through a major expansion of community health centers throughout this country.
Hillary is committed to seeing thousands of young doctors, nurses, psychologists, dentists and other medical professionals practice in underserved areas as we follow through on President Obama’s idea of tripling funding for the National Health Service Corps.
In New Hampshire, in Vermont and across the country we have a major epidemic of opiate and heroin addiction. People are dying every day from overdoses. Hillary Clinton understands that if we are serious about addressing this crisis we need major changes in the way we deliver mental health treatment. That’s what expanding community health centers will do and that is what getting medical personnel into the areas we need them most will do.
Hillary Clinton also understands that millions of seniors, disabled vets and others are struggling with the outrageously high cost of prescription drugs. She and I are in agreement that Medicare must negotiate drug prices with the pharmaceutical industry and that we must expand the use of generic medicine.
Drug companies should not be making billions in profits while one in five Americans are unable to afford the medicine they need. The greed of the drug companies must end.
This election is about the grotesque level of income and wealth inequality that currently exists, the worst it has been since 1928. Hillary Clinton knows that something is very wrong when the very rich become richer while many others are working longer hours for lower wages.
She knows that it is absurd that middle-class Americans are paying an effective tax rate higher than hedge fund millionaires, and that there are corporations in this country making billions in profit while they pay no federal income taxes in a given year because of loopholes their lobbyists created.
This election is about the thousands of young people I have met who have left college deeply in debt, the many others who cannot afford to go to college and the need for this country to have the best educated workforce in the world if we are to compete effectively in a highly competitive global economy.
Hillary Clinton believes that we must substantially lower student debt, and that we must make public colleges and universities tuition free for the middle class and working families of this country. This is a major initiative that will revolutionize higher education in this country and improve the lives of millions.
Think of what it will mean when every child in this country, regardless of the income of their family, knows that if they study hard and do well in school – yes, they will be able to get a college education and leave school without debt.
This election is about climate change, the greatest environmental crisis facing our planet, and the need to leave this world in a way that is healthy and habitable for our kids and future generations. Hillary Clinton is listening to the scientists who tell us that if we do not act boldly in the very near future there will be more drought, more floods, more acidification of the oceans, more rising sea levels.
She understands that we must work with countries around the world in transforming our energy system away from fossil fuels and into energy efficiency and sustainable energy – and that when we do that we can create a whole lot of good paying jobs.
This election is about the leadership we need to pass comprehensive immigration reform and repair a broken criminal justice system. It’s about making sure that young people in this country are in good schools or at good jobs, not in jail cells. Secretary Clinton understands that we don’t need to have more people in jail than any other country on earth, at an expense of $80 billion a year.”
Aaaand, you want to set up passwordless SSH for the remote hosts in your Ansible. There are lots of examples that involve file lookups for blah blah blah dot pub but why not just get a list from the agent?
A playbook:
- hosts: all
gather_facts: no
tasks:
- name: Get my SSH public keys
local_action: shell ssh-add -L
register: ssh_keys
- name: List my SSH public keys
debug: msg="{{ ssh_keys.stdout }}"
- name: Install my SSH public keys on Remote Servers
authorized_key: user={{lookup('env', 'USER')}} key="{{item}}"
with_items: "{{ ssh_keys.stdout }}"
The two tricky bits are:
1) Running a local_action to get a list of SSH keys.
2) Doing with_items to iterate if there are multiple keys.
A bonus tricky bit:
3) You may need to install sshpass if you do not already have key access to the remote servers. Last I knew, the brew command on Mac OS will balk at you for trying to install this.
In 2006, Sunnyvale applied for funding to add bicycle lanes on Maude Ave from Mathilda to Fair Oaks.
Maude is a two-lane road with a center turn lane. It serves as a main thoroughfare for the immediate neighborhood: residential, commercial, and Bishop Elementary. It also serves through traffic. It is very congested at peak. In the past three years there have been a few dozen accidents: mainly between vehicles, 3 involving pedestrians, 1 involving a cyclist.
W Maude Ave: filling in a gap in Sunnyvale’s bicycle network
In March 2016, a community meeting was held at Bishop school. Three main alternatives were proposed: Option 1: remove parking along Maude, replace it with 5′ bike lanes with 3′ buffers Option 2: retain parking, remove left-turn lanes, add bicycle lanes between driving and parking lanes Option 3: do nothing except add some signs and paint sharrows on the street
At the community meeting, many residents from the SNAIL neighborhood to the North took turns berating the city for any number of reasons. There was a lot of upset that Maude is already congested and that people might park in front of their homes. There was a “voting” board and the community poll came out something like:
Option 1: 35%
Option 2: 15%
Option 3: 50%
On April 21, 2016, the Sunnyvale Bicycle Pedestrian Advisory Committee (BPAC) reviewed the proposal. Some observations from BPAC:
Further detail desired regarding the causes of vehicle collisions along the corridor — details were not included in the present study.
Project should extend the last half block between Fair Oaks and Wolfe Road — staff remarked that this was an oversight on the original grant request, but that this could be included for future improvement projects to the bicycle infrastructure on Fair Oaks or Wolfe.
Drivers might park in buffered lanes.
If left turn lanes are removed, drivers might use the bicycle lane to pass vehicles waiting for turn.
Maude has many driveways, and it is safer for bicyclists further from the curb, where they are more visible to drivers utilizing driveways.
Traffic impact analysis will be performed subsequent to the city selecting a preferred alternative, thus no traffic impact studies have been performed to distinguish the current proposals.
1 mile between Mathilda and Fair Oaks 10 intersections 1 grammar school 3 pedestrian crosswalks
Community feedback:
I spoke first. I live adjacent to Bishop school:
I remarked on the lack of pedestrian crosswalks, asked the City to look at adding more as part of the project.
I noted the advantages of using the parking as a buffer lane for cyclists: route bike lanes at the curb.
I thanked BPAC for noting the desirability of an extension to Wolfe.
One gentleman who used to live in the neighborhood spoke in support of bike lanes.
One gentlemen from SNAIL explained his opposition to bike lanes, due to present low bicycle traffic.
One lady from Lowlanders spoke in support of a bike lane:
Leaning toward Option 2
Asked if there had been any Spanish-language outreach, as this is the population occupying the rental housing and attending Bishop who would be most impacted by the project, especially removal of parking.
BPAC made a motion to:
Support Option 1, per staff recommendation
Request 6′ bicycle lanes with 2′ buffer
Request project extension to Wolfe Road
Request inclusion of additional crosswalks
The motion passed with two dissenting votes. The chair, who lives on Murphy, stated his objections:
Removal of parking would adversely impact the neighborhood
Removal of left turn lanes would inconvenience drivers, and thereby discourage through traffic
I have misplaced my coffee mug. I’m glad to hear Ubuntu 16.04 LTS is out. “Codenamed ‘Xenial Xerus'” because computer people don’t already come off as a bunch of space cadets. Anyway, an under-caffeinated curmudgeon’s take:
The Linux kernel has been updated to the 4.4.6 longterm maintenance
release, with the addition of ZFS-on-Linux, a combination of a volume
manager and filesystem which enables efficient snapshots, copy-on-write
cloning, continuous integrity checking against data corruption, automatic
filesystem repair, and data compression.
Ah, ZFS! The last word in filesystems! How very exciting that after a mere decade we have stable support for it on Linux.
There’s a mention of the desktop: updates to LibreOffice and “stability improvements to Unity.” I’m not going to take that bait. No sir.
Ubuntu Server 16.04 LTS includes the Mitaka release of OpenStack, along
with the new 2.0 versions of Juju, LXD, and MAAS to save devops teams
time and headache when deploying distributed applications – whether on
private clouds, public clouds, or on developer laptops.
I honestly don’t know what these do, but my hunch is that they have their own overhead of time and headache. Fortunately, I have semi-automated network install of servers, Ganeti to manage VMs, and Ansible to automate admin stuff, so I can sit on the sidelines for now and hope that by the time I need it, Openstack is mature enough that I can reap its advantages with minimal investment.
Aside: My position on containers is the same position I have on Openstack, though I’m wondering if the containers thing may blow over before full maturity. Every few years some folks get excited about the possibility of reinventing their incumbent systems management paradigms with jails, burn a bunch of time blowing their own minds, then get frustrated with the limitations and go back to the old ways. We’ll see.
Anyway, Ubuntu keeps delivering:
Ubuntu 16.04 LTS introduces a new application format, the ‘snap’, which
can be installed alongside traditional deb packages. These two packaging
formats live quite comfortably next to one another and enable Ubuntu to
maintain its existing processes for development and updates.
YES YES YES YES YES YES YES OH snap OH MY LERD YES IF THERE IS ONE THING WE DESPERATELY NEED IT IS YET ANOTHER WAY TO MANAGE PACKAGES I AM TOTALLY SURE THESE TWO PACKAGING FORMATS WILL LIVE QUITE COMFORTABLY TOGETHER next to the CPANs and the CRANs and the PIPs and the … don’t even ask how the R packages work …
Further research reveals that they’ve replaced Python 2 with Python 3. No mention of that in the email announcement. I’m totally sure this will not yield any weird problems.
I am having a tricky time with Ganeti, and the mailing list is not proving helpful. One factor is that I have two different versions in play. How does one divine the differences between these versions?
Git to the rescue! Along these lines:
git clone git://git.ganeti.org/ganeti.git # Clone the repo ...
cd ganeti
git branch -a # See what branches we have
git ls-remote --tags # See what tags we have
git checkout tags/v2.12.4 # Check out the "old" branch/tag
git diff tags/v2.12.6 # Diff "old" vs "new" branch/tag
# OH WAIT, IT IS EVEN EASIER THAN THIS! (Thanks, candlerb!)
# You don't hack to check out a branch, just do this:
git diff v2.12.4 v2.12.6 # Diff "old" vs "new"
And now I see the “diff” between 2.12.4 and 2.12.6, and the changes seem relevant to my issue.
In my mind, what is most unfortunate about that setup, is they did not get to experience Dial Up Networking via a modem. I think they would have been truly blown away. Alas, the Internet contains wonders, like this guy getting a 50 year old modem to work:
What could be more amazing than that? How about this guy, with a 50 year old modem and a teletype, browsing the first web site via the first web browser, by means of a punch tape bookmark?
I wanted to share a clever load balancer config strategy I accidentally discovered. The use case is you want to make a web service available to clients on the Internet. Two things you’ll need are:
1) an authentication mechanism
2) encrypted transport (HTTPS)
You can wrap authentication around an arbitrary web app with HTTP auth. Easy and done.
For encrypted transport of web traffic, I now love sslmate is the greatest thing since sliced bread. Why?
1) Inexpensive SSL certs.
2) You order / install the certs from a command line.
3) They feed you the conf you probably need for your software.
4) Then you can put the auto-renew in cron.
So, for example, an nginx set up to answer on port 443, handle the SSL connection, do http auth, then proxy over to the actual service, running on port 12345:
The clever load balancer config? The health check is to hit the server(s) in the pool, request / via HTTPS, and expect a 401 response. The load balancer doesn’t know the application password, so if you don’t let it in, you must be doing something right. If someone mucks with the server configuration and disables HTTP AUTH, then the load-balancer will get 200 on its health checks, regard success as an error, and “fail safe” by taking the server out of the pool, thus preventing people from accessing the site without a password.
Tell the load balancer that success is not an acceptable outcome
I finally caught a Democratic Debate last night, thanks to a gracious wife who helped our son to bed. I’m a Sanders guy, I send him $25/mo. I recently read that he’s the only candidate who pays his interns, which I like for several reasons: economic opportunity for young folks, which our country needs, and my hunch is that someone getting the opportunity to earn a paycheck is going to have a little more earnestness than a more privileged kid who is taking the job to build a resume. Even more, it puts a price on one’s commitment: time is at a premium for me, but my $25/mo should cover two hours of intern labor. I feel a connection …
At the debate, I was a little disappointed in Bernie. Ask him a question, ask for details, and he’d pivot to any one of several talking points about how we need to regulate the banks, shut down the prisons, hand out tuition … he is an idealist but he is still a politician.
Presidential Debate Summary: mostly partisan, indecipherable yelling and screaming from a hangry toddler of undeclared political alignment.
Hillary, I like her fine enough. She had to go ahead and congratulate herself for being in the Situation Room to get Osama killed. Who wouldn’t brag about that one? Then near the end she tried to paint Bernie as a guy who is all busy hating on Obama. Bernie had a good retort that is was Hillary who ran against him in 2008.
The weirdest part was when Bernie started going off about Henry Kissinger. The gist of it is that the man is a war criminal and pals with Clinton. Maybe he could goad her into defending a war criminal? She handled that deftly: she’ll take advice from anyone. I’m no Kissinger fan but that was one of several times when Bernie’s focus seemed more on the mid-20th century than the present day. I appreciate historical perspective, but I worry about the guy coming off as stuck in the past.
I found a good explanation on the Kissinger thing here at “The Intercept”. The gist of it is that yes, Kissinger is an impressively heinous character and a friend of Hillary Clinton, and that there is a larger issue, that Left or Right, there’s a little cabal of hawkish Neocon-leaning foreign policy advisors that make up the Washington Foreign Policy Establishment. Bernie has been dinged for not articulating his vision for foreign policy, but when he lights up on Kissinger, he’s using Kissinger as the bellwether poster child for the Foreign Policy Establishment. He’s essentially saying what he says on a lot of stuff: we can do better.
The test of a great and powerful nation is not how many wars it can engage in, but how it can resolve international conflicts in a peaceful manner. I will move away from a policy of unilateral military action and regime change, and toward a policy of emphasizing diplomacy, and ensuring the decision to go to war is a last resort.
As secretary of state, I worked to restore America’s leadership in the world. As president, defending our values and keeping us safe will be my top priority. That includes maintaining a cutting-edge military, strengthening our alliances, cultivating new partners, standing up to aggressors, defeating ISIS, and enforcing the Iran nuclear agreement.
“Keep us safe! More military! Defeat ISIS and watch our for Iran!”
Obama’s disengagement has contributed to growing threats to our national security, including radical Islamic terrorism, Iranian aggression, an emboldened Putin, and an assertive China. Adversaries do not fear us and allies do not trust us. I will rebuild America’s military, restore our credibility and leadership, and repair our broken alliances.
“Muslims! Iran! Russia! China! More military!”
It would seem that this isn’t about Bernie being stuck in the 20th Century. Bernie’s beef is that Washington is stuck in the late 20th Century. The same advice that got us in bed with the Shah of Iran, that stoked the revolution there, is the same advice that got us mired in Vietnam and armed Al Qaeda, is the same advice that later got us mired in Iraq, and it is this same advice that is likely to bite us in the future.
I think one could debate the merits of interventionism versus the blowback and unintended consequences. Okay, Kissinger is a bad guy: I get it. Bernie, what should we do different and how do you honestly figure it will play out? Americans are not naturally fond of interventionism, but it seems to have worked well enough for us most days. Most days, it is foreigners who pay the price. Foreigners … and our soldiers. In Vietnam it was The Draft and it seems that everyone in my parents’ generation carries some subtle emotional scar from that. Foreigners, soldiers, conscripts … on 9/11 it was office workers, police and firefighters. But we don’t talk about 9/11 as blowback for interventionism.
Indeed, Sanders said, “I supported the use of force in Afghanistan to hunt down the terrorists who attacked us.”
Sanders said the war with the terror organization, which released videos this week that threatened attacks in Washington and New York, “must be done primarily by Muslim nations with the strong support of their global partners.”
“The war against ISIS, a brutal and dangerous organization, cannot be won unless the Muslim nations which are most threatened — Saudi Arabia, Kuwait, Qatar, Turkey, Iran and Jordan — become fully engaged, including the use of ground troops,” Sanders said.
“It must be destroyed not just by the United States of America alone. In many respects, what ISIS wants is a clash of civilizations,” Sanders said.
“With the third largest military budget in the world and an army far larger than ISIS, the Saudi government must accept its full responsibility for stability in their own region of the world,” he added
But, Sanders added: “I oppose, at this point, a unilateral American no-fly zone in Syria, which could get us more deeply involved in that horrible civil war and lead to a never-ending U.S. entanglement in that region.”
“I fear very much that supporting questionable groups in Syria who will be outnumbered and outgunned by both ISIS and the Assad regime could open the door to the United States once again being dragged back into the quagmire of long-term military engagement,” he said.
In a later tweet, Sanders insisted, “We will not destroy ISIS by undermining the Constitution and our religious freedoms.”
From what I can see, Bernie articulates what sounds to me some reasonable ideas about foreign policy. Nations have to take care of their own regional problems. We should help out. But we can’t win what isn’t really our fight.
To support troops from Iraq and around the region, the U.S. should “immediately deploy the special operations force President Obama has already authorized and be prepared to deploy more as more Syrians get into the fight,” Clinton said.
On ABC, Clinton said: “We have to fight in the air, fight on the ground and fight them on the Internet. We have to do everything we can with our friends and partners around the world. That’s what we’ll hear from the president, to intensify the current strategy.”
Yet Clinton cynically told corporate executives at a 2011 State Department roundtable on investment opportunities in Iraq, “It’s time for the United States to start thinking of Iraq as a business opportunity.”
Oh Google, your algorithms seem to have a Socialist bias. At any rate, I feel better about where my sympathies lie.






















{kind=link}
{kind=link}
{kind=link}
{kind=link}