A troop of lone-tein (riot police comprised of paid thugs) protected by the military trucks, raided the monastery with 200 studying monks. They systematically ordered all the monks to line up and banged and crushed each one’s head against the brick wall of the monastery. One by one, the peaceful, non resisting monks, fell to the ground, screaming in pain. Then, they tore off the red robes and threw them all in the military trucks (like rice bags) and took the bodies away.
The head monk of the monastery, was tied up in the middle of the monastery, tortured , bludgeoned, and later died the same day, today. Tens of thousands of people gathered outside the monastery, warded off by troops with bayoneted rifles, unable to help their helpless monks being slaughtered inside the monastery. Their every try to forge ahead was met with the bayonets.
When all is done, only 10 out of 200 remained alive, hiding in the monastery. Blood stained everywhere on the walls and floors of the monastery.
There are some pretty nasty photographs on that page, and video of civilians falling to gunfire.
I’ve got a MySQL slave server, and Seconds_Behind_Master keeps climbing. I repaired some disk issues on the server, but the replication lag keeps increasing and increasing. A colleague explained that several times now he has seen a slave get so far behind that it is completely incapable of catching up, at which point the only solution is to reload the data from the master and re-start sync from there. This isn’t so bad if you have access to the innobackup tool.
The server is only lightly loaded. I like to think I could hit some turbo button and tell the slave to pull out all the stops and just churn through the replication log and catch up. So far, I have some advice:
2) MySQL suggest that you can improve performance by using MyISAM tables on the slave, which doesn’t need transactional capability. But I don’t think that will serve you well if the slave is intended as a failover service.
Your options are fairly limited. You can monitor how far behind the slave is . . . and assign less work to it when it starts to lag the master a lot . . . You can make the slave’s hardware more powerful . . . If you have the coding kung-fu, you might also try to “pipeline the relay log.”
After yesterday’s post, I figured I would have to re-synchronize the slave database from the master, but probably build a more capable machine before doing that. I figured at that point, I might as well try fiddling with MySQL config variables, just to see if a miracle might happen.
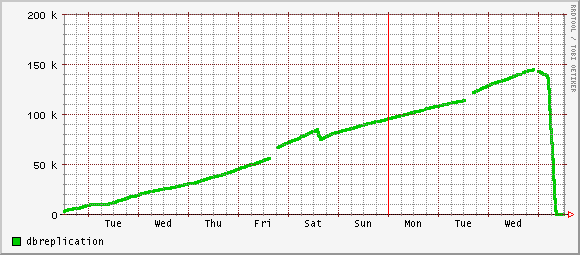
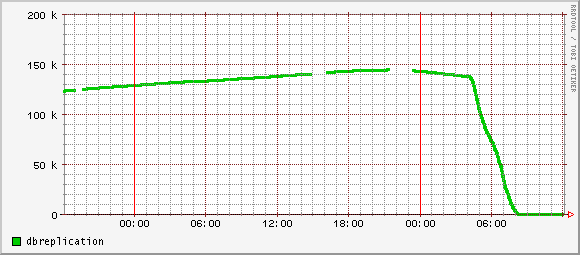
At first I twiddled several variables, and noticed only that there was less disk access on the system. This is good, but disk throughput had not proven to be the issue, and replication lag kept climbing. The scientist in me put all those variables back, leaving, for the sake of argument, only one changed.
This morning as I logged in, colleagues asked me what black magic I had done. Check out these beautiful graphs:
The default value of this variable is 1, which is the value that is required for ACID compliance. You can achieve better performance by setting the value different from 1, but then you can lose at most one second worth of transactions in a crash. If you set the value to 0, then any mysqld process crash can erase the last second of transactions. If you set the value to 2, then only an operating system crash or a power outage can erase the last second of transactions. However, InnoDB’s crash recovery is not affected and thus crash recovery does work regardless of the value. Note that many operating systems and some disk hardware fool the flush-to-disk operation. They may tell mysqld that the flush has taken place, even though it has not. Then the durability of transactions is not guaranteed even with the setting 1, and in the worst case a power outage can even corrupt the InnoDB database. Using a battery-backed disk cache in the SCSI disk controller or in the disk itself speeds up file flushes, and makes the operation safer.
The Conventional Wisdom from another colleague: You want to set innodb_flush_log_at_trx_commit=1 for a master database, but for a slave–as previously noted–is at a disadvantage for committing writes, it can be entirely worthwhile to set innodb_flush_log_at_trx_commit=0 because at the worst, the slave could become out of sync after a hard system restart. My take-away: go ahead and set this to 0 if your slave is already experiencing excessive replication lag: you’ve got nothing to lose anyway.
(Of course, syslog says the RAID controller entered a happier state at around the same time I set this variable, so take this as an anecdote.)