Link:
https://dannyman.toldme.com/2008/02/01/please-stay-yahoo/
Much buzz about Microsoft’s offer to buy Yahoo!
I am a big fan of Google and their myriad products, but sometimes they get on my nerves. I like having Yahoo! as an alternative. I love Flickr. I would hate to see Yahoo! swallowed up my Microsoft, leaving the biggest players on the Internet being a choice between the Google and the Microsoft.
I prefer an online world that isn’t simply black and white, but which also has a weird shade of purple to it.
Feedback Welcome
Link:
https://dannyman.toldme.com/2008/01/26/deader-than-amiga/
I have been playing with Google Trends, which will be happy to generate a pretty graph of keyword frequency over time. A rough gauge to the relative popularity of various things. This evening, I was riffing off a post from the Royal Pingdom, regarding the relative popularity of Ubuntu and Vista, among other things.
I got started graphing various Linux distributions against each other, XP versus Vista, and trying to figure out the best keyword for OS X. Then, I wondered about FreeBSD. Against Ubuntu, it was a flatline. So, I asked myself: what is the threshold for a dead or dying Operating System?
Amiga vs FreeBSD:
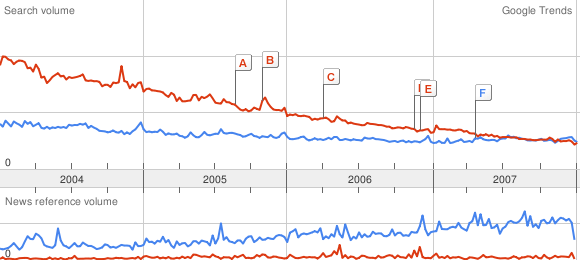
Ouch! Can we get deader?
Amiga vs FreeBSD vs BeOS:
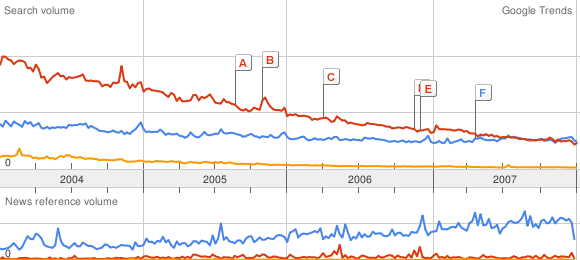
To be fair, the cult of Amiga is still strong . . . BeOS is well and truly dead. But how do the BSDs fare?
Amiga vs FreeBSD vs BeOS vs NetBSD vs OpenBSD:
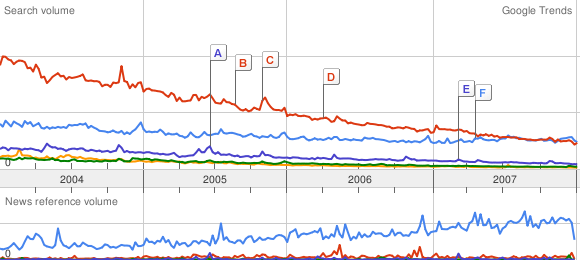
NetBSD has been sleeping with the BeOS fishes for a while, and OpenBSD is on its way. And that’s a league below Amiga!
In Red Hat land, only Fedora beats “the Amiga Line”. For Unix in general, nothing stops the Ubuntu juggernaut. But there’s a long way to go to catch up with Uncle Bill.
(Yes, it is a rainy night and the girlfriend is out of town.)
Postscript: Ubuntu versus Obama
3 Comments
Link:
https://dannyman.toldme.com/2008/01/26/notchup-launch-interview/
I just got an invitation to join NotchUp. Wary of the latest craze in data mining masked as social networking I did a quick Google search. TechCrunch had the best summary.
We’re basically looking at LinkedIn (they even import your LinkedIn profile) except that you can set a price at which you would be willing to interview with a prospective employer. The idea being, maybe you are happy where you are but you’d be happy to talk about being somewhere else, though your time is valuable. (Employers, of course, already know that recruiting is an expensive undertaking . . . it is not hard to see them pony up . . .)

Apparently this is from “Peerflix refugees” so I’d peg it as “an interesting innovation that rips off an existing proven idea that is probably ahead of their ability to execute.”
I accepted the invite, to check it out but mainly so I could invite a friend who is job hunting. I figured if Powerset and Yahoo giving it a go . . .
First Impressions:
- Very rough: when I declined to invite everyone I know on LinkedIn the site closed its own window.
- Lame: the “invite-only preview” site is protected by a shared HTTP authentication username and password . . . then you log in.
- Also Lame: you can’t view any of their web site (like “About Us”) without the HTTP authentication credentials. Amateurs!
- Steals your LinkedIn profile very nicely, but requires your password. Wonder how soon LinkedIn will block them.
- I don’t see why LinkedIn couldn’t just add the “set price to interview” as a feature within about two months.
- Feels very much like a LinkedIn rip-off.
- Snickering towards Doom: Their own “Jobs” page reads, in total: “VP of Business Development”
- Doomed: The site is very slow, even as a limited preview. Methinks their engineers aren’t so great.
Actually, now I feel dirty. I’m changing my LinkedIn password . . .
8 Comments
Link:
https://dannyman.toldme.com/2008/01/23/vim-increment-decrement-integers/
I have been using Vim for years, and have any number of times (say, when dealing with DNS configuration) had to edit many lines, changing integers by a constant value, and it was always a hassle to repeatedly switch modes and type in a new number. “There must be some macro or other special mojo,” I thought, “and sometime, I will figure this out.”
Well, there is special mojo, and the figuring it out is so dead simple I kick myself for not knowing this years ago:
Vim Tip 287: Cool trick to change numbers
- You can increment a number with control A
- You can decrement a number with control X
- If the cursor is not already on a number, either of these will advance the cursor to the next number
- This does the math for multi-column numbers!
Yes, I rated that tip as “life changing”!
1 Comment
Link:
https://dannyman.toldme.com/2008/01/17/tellme-get-hired/
So, in the unlikely event that you are reading this, and trying to score a job at Tellme, I stumbled upon a little tip while trying to debug something else: check out their HTTP headers, particularly the X-Great-Jobs: header.
I got hired there back when it was in stealth mode, and they left a “secret” message as an HTML comment on the front page of the web site. It is nice to see an old tradition is still around. It is also weird to see that their present “cover image” is an intersection on the same street my grammar school was on, back in Chicago.
1 Comment
Link:
https://dannyman.toldme.com/2008/01/11/etc-crontab-or-die/
This is just a note which I contributed to a thread on sage-members, to get something off my chest, as to where people should maintain their crontab entries. I sincerely doubt that reading what I have to say will bring you any great illumination.
I’d say, any reasonable SysAdmin should default to /etc/crontab because every other reasonable SysAdmin already knows where it is. If anything is used in addition to /etc/crontab, leave a note in /etc/crontab advising the new guy who just got paged at 3:45am where else to look for crons.
For production systems, I strongly object to the use of per-user crontabs. I’m glad to hear I’m not alone. One thing I have to do in a new environment tends to be to write a script that will sniff out all the cron entries.
And then there was the shop that used /etc/crontab, user crons, and fcron to keep crons from running over each other. This frustrated me enough that I did a poor job of explaining that job concurrency could easily be ensured by executing a command through (something like) the lockf utility, instead of adding a new layer of system complexity.
Yes, I am a cranky old SysAdmin.
2 Comments
Link:
https://dannyman.toldme.com/2008/01/08/bill-gates-last-day/
I was startled by this YouTube video, where we discover that Bill Gates can make fun of himself. Or, at least, his people can assemble a video where Bill Gates makes fun of himself. Good for Bill! I was then reassured at the consistency of the universe, when it was revealed that Bill really can’t make fun of himself without at least a dozen star cameos to reassure us that it is not so much that he is poking fun at himself, but that he is “acting”.
It is telling that Al Gore has the funniest line.
I hope Bill’s foundation does much good in the world. I almost feel sorry for Microsoft that after all the effort, Vista has proven to be a cold turkey. For what its worth, from a UI and performance perspective, I prefer Windows XP to Mac OS X. Though I’m not sure that this is praise for Microsoft as much as it is an aversion to the Smug Cult of Apple.
(Yes, I am a contrarian. People hate contrarians. Especially Mac people, who think they have the contrarian cred: the last thing a contrarian wants to encounter is a contradicting contrarian!)
Feedback Welcome
Link:
https://dannyman.toldme.com/2007/12/04/tip-manage-infinite-passwords/
Problem: You have logins to a bajillion things and that is too many unique passwords to remember. Maybe you remember a half dozen passwords, if you’re lucky, but you would prefer to have a unique password for each account so the hackers can’t get you.
One approach is to always generate a new password when you get access to a new account, and store that somewhere safe. Sticky notes on your monitor? A GPG-encrypted file with a regularly-changing hash? Either way, you have to account for what happens if someone else gets access to your password list, or you yourself can not access this password list. I am not fond of this approach.
My Tip: I suggest instead of storing passwords, you come up with a couple of ways to “hash” unique passwords depending, on say, a web site’s name.
For example, if you were really lame, and you used the password “apple” for everything, you’d make things better if instead, say, you replaced the the ‘pp’ part with the first three letters of your web site’s name.
For example:
Yahoo: “apple” becomes “ayahle”
Google: “apple” becomes “agoole”
Amazon: “apple” becomes “aamale”
MSN: “apple” becomes “amsnle”
Apple: “apple” becomes “aapple”
Now, you can get a lot more creative than that, like using a non-dictionary word, mixing up letter cases and punctuation, etc.
Try a more advanced hash:
– Start with a pass-phrase “apples are delicious, I eat one every day”
– Take the last letter from each word: “sesiteyy”
– Capitalize the last half of the passphrase: “sesiTEYY”
– Stick the first three letters of the web site’s name in the middle: “sesi___TEYY”
– If the third letter you insert is a vowel, follow it with a “!” otherwise, add an “@”
– Change the first letter that you can from the substitution: a becomes a 4, e becomes a 3, i becomes a 1, and o becomes a zero
Now you get:
Yahoo: sesiy4h@TEYY
Google: sesig0o!TEYY
Amazon: sesi4ma!TEYY
MSN: sesimsn@TEYY
Apple: sesi4pp@TEYY
It is best if you have a few different schemes you can use: some web sites reject strong passwords, so having a really bad password handy is good, and some places you’ll want extra secure. For example, use a different “hash” for your bank passwords, just in case your “every day” hash is compromised.
3 Comments
Link:
https://dannyman.toldme.com/2007/11/02/use-the-source-luke/
I have been following the “One Laptop per Child” project for a while now, formerly known as the “Hundred Dollar Laptop” project, though right now the price comes in closer to $200 . . . in November I am looking forward to getting my hands on one with the “Give One Get One” program. I enjoy following developments on the “OLPC News” blog. Today I learned that Microsoft is scrambling resources to shoehorn its normally-bloated Windows Operating System onto this lightweight gem. That makes me smile because it is usually the case that computers like the laptop I am typing on right now are “Designed for Windows(R) XP” or the like, and it is the Open Source community that must scramble to reverse-engineer and build drivers for the new hardware.
Anyway, I was just looking at a post that suggests that since the OLPC is rather ambitious, technologically and culturally, they have no qualms about redesigning the keyboard: no more CAPS LOCK but instead a mode to shift between Latin alphabet and the local alphabet. Also, perhaps, a “View Source” key: which could perhaps allow kids to poke under the Python hood and check out the code that is running underneath. My goodness!
There are some good comments there! I just added my own:
I’d like to chime in with a “me too” . . . sure most people don’t find much use for the hood latch on a car, but we’re glad it is there: it allows us to get in if we need to. For the smaller number of people who DO want to play under the hood, the hood release is invaluable. We all learn differently and and those who are going to get into computers ought to be given the access and encouragement to learn.
I played with computers for a decade before I learned to program. Maybe a “view source” key might have gotten me going faster.
As for code complexity: you can still view the source on this very page and understand much of it. I understand that Python is constrained to 80 columns and is highly highly readable.
As for breaking things: EXACTLY!! The kids ought to have access to break the code on their computers. Rather than turning them in to worthless bricks: worst case you reinstall the OS! Talk about a LEARNING experience!! Anyway, programmers use revision control: hopefully an XO could provide some rollback mechanism. :)
It should also be good for long-term security … people will learn that computers execute code, and code can have flaws an exploits. If the kids can monkey with their own code, you KNOW they’re going to have some early transformative learning experience NOT to paste in “cool” code mods from the Class Hacker. ;)
Cheers,
-danny
Feedback Welcome
Link:
https://dannyman.toldme.com/2007/10/04/a-small-mysql-miracle/
After yesterday’s post, I figured I would have to re-synchronize the slave database from the master, but probably build a more capable machine before doing that. I figured at that point, I might as well try fiddling with MySQL config variables, just to see if a miracle might happen.
At first I twiddled several variables, and noticed only that there was less disk access on the system. This is good, but disk throughput had not proven to be the issue, and replication lag kept climbing. The scientist in me put all those variables back, leaving, for the sake of argument, only one changed.
This morning as I logged in, colleagues asked me what black magic I had done. Check out these beautiful graphs:
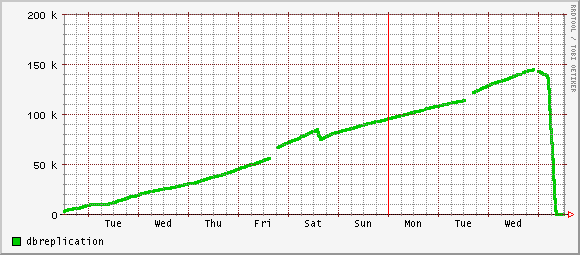
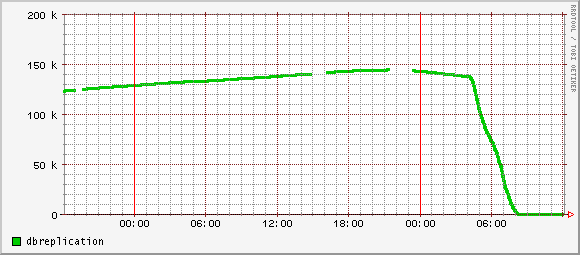
Rather dramatic. The change?
#set-variable = innodb_flush_log_at_trx_commit=1
set-variable = innodb_flush_log_at_trx_commit=0
The weird thing is that things did not begin to improve until about twelve hours after I made the change, so . . . ?
The schtick with innodb_flush_log_at_trx_commit:
The default value of this variable is 1, which is the value that is required for ACID compliance. You can achieve better performance by setting the value different from 1, but then you can lose at most one second worth of transactions in a crash. If you set the value to 0, then any mysqld process crash can erase the last second of transactions. If you set the value to 2, then only an operating system crash or a power outage can erase the last second of transactions. However, InnoDB’s crash recovery is not affected and thus crash recovery does work regardless of the value. Note that many operating systems and some disk hardware fool the flush-to-disk operation. They may tell mysqld that the flush has taken place, even though it has not. Then the durability of transactions is not guaranteed even with the setting 1, and in the worst case a power outage can even corrupt the InnoDB database. Using a battery-backed disk cache in the SCSI disk controller or in the disk itself speeds up file flushes, and makes the operation safer.
The Conventional Wisdom from another colleague: You want to set innodb_flush_log_at_trx_commit=1 for a master database, but for a slave–as previously noted–is at a disadvantage for committing writes, it can be entirely worthwhile to set innodb_flush_log_at_trx_commit=0 because at the worst, the slave could become out of sync after a hard system restart. My take-away: go ahead and set this to 0 if your slave is already experiencing excessive replication lag: you’ve got nothing to lose anyway.
(Of course, syslog says the RAID controller entered a happier state at around the same time I set this variable, so take this as an anecdote.)
2 Comments
Link:
https://dannyman.toldme.com/2007/10/03/seconds-behind-master-never-catches-up/
I’ve got a MySQL slave server, and Seconds_Behind_Master keeps climbing. I repaired some disk issues on the server, but the replication lag keeps increasing and increasing. A colleague explained that several times now he has seen a slave get so far behind that it is completely incapable of catching up, at which point the only solution is to reload the data from the master and re-start sync from there. This isn’t so bad if you have access to the innobackup tool.
The server is only lightly loaded. I like to think I could hit some turbo button and tell the slave to pull out all the stops and just churn through the replication log and catch up. So far, I have some advice:
1) Eric Bergen explains that the reason it keeps falling further behind is because the slave server can only process queries sequentially, whereas the master database processes queries in parallel.
2) MySQL suggest that you can improve performance by using MyISAM tables on the slave, which doesn’t need transactional capability. But I don’t think that will serve you well if the slave is intended as a failover service.
Xaprb explains this well, then goes on to say:
Your options are fairly limited. You can monitor how far behind the slave is . . . and assign less work to it when it starts to lag the master a lot . . . You can make the slave’s hardware more powerful . . . If you have the coding kung-fu, you might also try to “pipeline the relay log.”
That pipeline approach sounds like the YouTube way.
Update: to my surprise, things got better!
1 Comment
Link:
https://dannyman.toldme.com/2007/09/19/on-call/
As of 11AM this morning, and until 11AM next Tuesday, I’m “on call” . . . which means that if something breaks, especially at 3AM, I’m the first guy responsible for fixing it.
This is actually a new form of “on call” for me–this is the first time I have been in a “rotation”. At other, smaller companies, I have spent years on-call. Now, that isn’t quite so bad in a small environment where things seldom fail, but it is something of a drag to keep your boss informed of your weekend travel plans so he can watch for pages in your stead. In a larger environment, a week spent on-call can be particularly onerous, because there are plenty of things that will break. But, come the end of the week, you pass the baton . . .
So, this week, I will get my first taste, and over time I will have a better sense as to whether “on call” is better in a smaller environment or a larger environment. I have a feeling that while this week could be rough, that the larger environment is an overall better deal: there is a secondary on-call person, there is an entire team I can call for advice on different things, and the big company provides nice things like a cellular modem card, and bonus pay for on-call time.
Hoo-rah!!
1 Comment
Link:
https://dannyman.toldme.com/2007/08/22/sh-split-via-set/
Recently, I wrote a shell script that had to break an IP address into octets. I wrote:
# octects
oct1=`echo $subnet | awk -F . '{print $1}'`
oct2=`echo $subnet | awk -F . '{print $2}'`
oct3=`echo $subnet | awk -F . '{print $3}'`
oct4=`echo $subnet | awk -F . '{print $4}'`
Later, when reviewing my script, Anonymous Coward offered this little gem:
$ set `echo 10.20.30.40 | tr '.' ' '`
$ echo $1
10
$ echo $2
20
$ echo $3
30
$ echo $4
40
Which means, you can just set a series of variables to $1, $2, $3, and so forth. In Anon’s example, the IP address is split into words with tr, and the variables set nice and easy with set.
Of course, if your script gets complex, you probably want to avoid relying on those variables. My original code could be re-expressed:
set `echo $subnet | tr '.' ' '`
oct1=$1; oct2=$2; oct3=$3; oct4=$4
Much nicer than invoking awk several times.
3 Comments
Link:
https://dannyman.toldme.com/2007/08/21/geeks-fight-back/
So, this is neat.
Big companies like to try to control consumers with new technology. Consumers invariably defeat this technology. Copy-protected video cassettes, CDs, DVDs . . . DVD “regions” so that a DVD bought in one part of the world can’t play in another part of the world, and of course, you can’t play DVDs on Linux . . . but faster and faster all these restrictions get hacked away with software. The geeks have an understanding that a new technology isn’t really useful until the “Digital Rights Management” has been defeated.
I read, the other day, in the O’Reilly Radar blog, that simple electronic “hack” gadgets are getting cheaper, and more commercialized. Just now I read of a new consumer hack to unlock iPhones from requiring AT&T service. This is a neat step in the efforts of geeks and consumers to wrestle control away from another industry full of big companies that would prefer to limit consumer freedom. A neat confluence.
The big corporation Google has been trying to fight, ostensibly, on our behalf as well, convincing Congress to sell new radio spectrum for use with open standards, which would give us more raw material to work with that isn’t managed by the big telephone companies. Exciting, esoteric struggles afoot, and you know who I’m rooting for!
-danny
Feedback Welcome
Link:
https://dannyman.toldme.com/2007/08/13/sysadmin-chaos/
Getting a handle on the new job, reading up at infrastructures.org:
In the financial industry, generally accepted accounting practices call for double-entry bookkeeping, a chart of accounts, budgets and forecasting, and repeatable, well-understood procedures such as purchase orders and invoices. An accountant or financial analyst moving from one company to another will quickly understand the books and financial structure of their new environment, regardless of the line of business or size of the company.
There are no generally accepted administration procedures for the IT industry. Because of the ad-hoc nature of activity in a traditional IT shop, no two sets of IT procedures are ever alike. There is no industry-standard way to install machines, deploy applications, or update operating systems. Solutions are generally created on the spot, without input from any external community. The wheel is invented and re-invented, over and over, with the company footing the bill. A systems administrator moving from one company to another encounters a new set of methodologies and procedures each time.
[. . .]
This means that the people who are drawn to systems administration tend to be individualists. They are proud of their ability to absorb technology like a sponge, and to tackle horrible outages single-handedly. They tend to be highly independent, deeply technical people. They often have little patience for those who are unable to also teach themselves the terminology and concepts of systems management. This further contributes to failed communications within IT organizations.
Caveat SysAdmin. It’s just the price we pay for working in a nascent field.
Feedback Welcome
« Newer Stuff . . . Older Stuff »
Site Archive