Link:
https://dannyman.toldme.com/2026/03/06/remove-the-ask-gemini-button/
Easy: right-click on “Ask Gemini” and select “Unpin”

Right-click “Ask Gemini” and select “Unpin” …
… and the “Ask Gemini” button is gone! Poof!!
Yet another dull anecdote about Google sucking at UI:
I tried to ask Gemini by clicking the “Ask Gemini” button but it asked me for permission to spy on my stuff and I said no and so it wouldn’t let me ask anything of them.
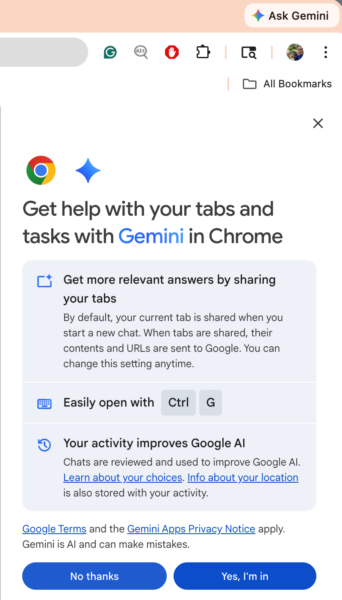
In my country, Gemini asks you!
So I asked a Search Engine (Kagi) and it pulled up a Reddit post.
Sometimes, the old ways still work best!
Feedback Welcome
Link:
https://dannyman.toldme.com/2026/03/05/todays-mastodon-tweaks/
Today I learned how to set up “author attribution” for links to your web site attached to Mastodon posts. I discovered this after sharing a link to ploum on my Mastodon.
Thank you, @14mission for testing the attribution feature for me!
This is a very humane feature, I think. If someone shares your content then Mastodon helps you to connect with their social media profile.
Then I got to thinking about how there are accounts on Mastodon that basically mirror Bluesky. But I never check or post to Bluesky. I could mirror my Mastodon to Bluesky? Yes! Skymoth was super easy to set up. Nice!
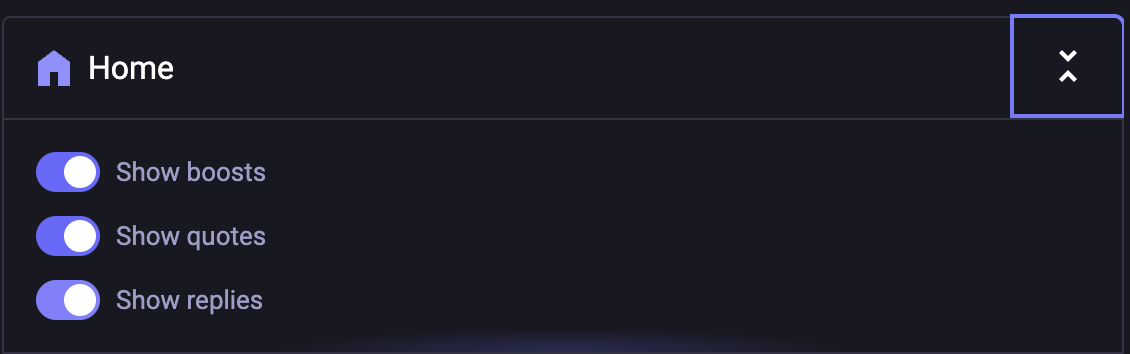
I was chatting on Discord and a friend said he wanted to see Mastodon without re-toots. Bluesky has a nice OnlyPosts feature but then I spotted the applicable feature in the Mastodon UI.
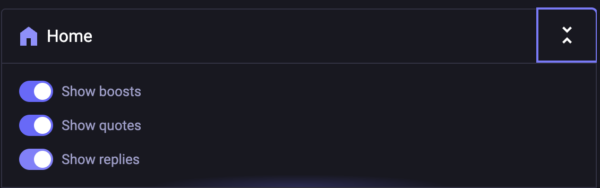
Squeeze the “two carats” element to get a submenu.
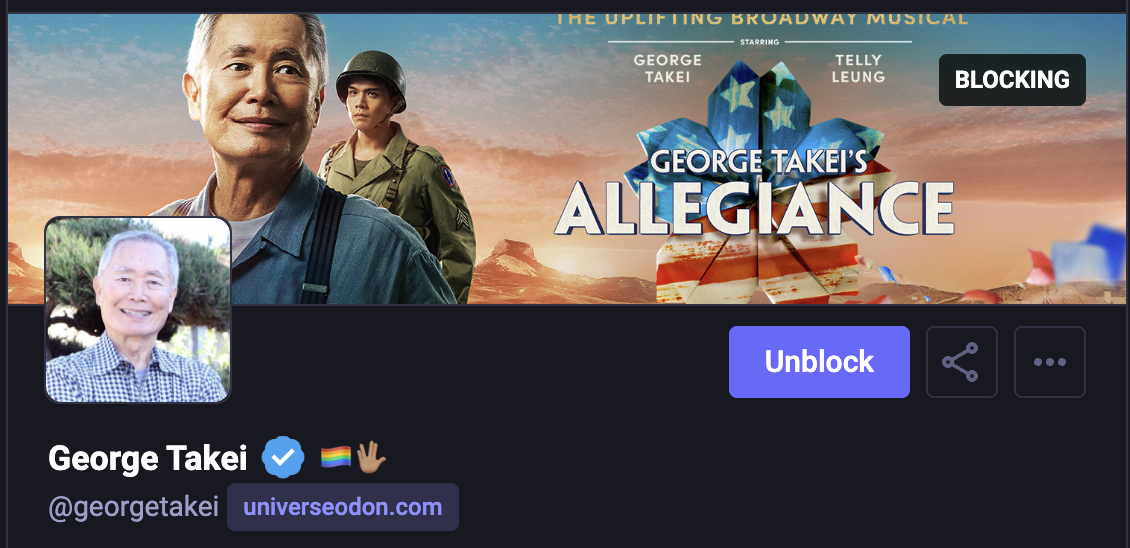
That left me with one last grouse I have had about Mastodon: the one thing I can not easily block is re-toots of screenshots of X. Or can I? Well, I think I effectively can. The secret is that stuff is mostly re-toots of George Takei, so blocking muting George Takei ought to do the trick.
George Takei is great but his social media is too much.
Now, I love George Takei as much as anyone. Unfortunately, his social media is a barrage of stuff I don’t want to see that is frequently re-posted. This technique is probably applicable for other popular folks as well.
Feedback Welcome
Link:
https://dannyman.toldme.com/2025/07/01/tip-remind-the-user-theyre-working-in-production/
This has now come up more than once in my career, so I thought I would share.
A common practice is to have different instances of the same web-based software running in your dev, stage, test, and production environments. You test changes in dev, and on occasion you press the big scary button in prod. The problem is, of course, these sites look very much the same from browser tab to browser tab and it is possible to run the wrong thing in the wrong time in the wrong environment.
So, a fix I concocted about twenty years ago, and again recently, is to skin in a background tile to a production environment, that cautions a user that they’re in production. The design is “very light red” to replace a white background, but also the word “prod” in a slightly darker color, to add a bit of emphasis, and to ensure compatibility with our color blind friends.

Tile the phrase “prod” in a stagger across the background of a sensitive web site to instill caution.
Upload the file, and add this to the site’s CSS:
BODY { background-color: #ffdddd; background-image: url(“/images/prod.png”); background-attachment: fixed; }
And, you are done! You can see a “demo” on this blog entry. Thanks to Google Gemini for telling me how to slide CSS declarations in via HTML from within a document body using JavaScript. I hate AI so it is a nice little thrill when it provides actual value.
The background-attachment: fixed cause the background to not scroll in the viewport. I think this makes it more noticeable and also allows the user to scroll past potential readability issues triggered by the background graphic.
Feedback Welcome
Link:
https://dannyman.toldme.com/2025/03/04/2025-02/
2025-02-04 Tuesday
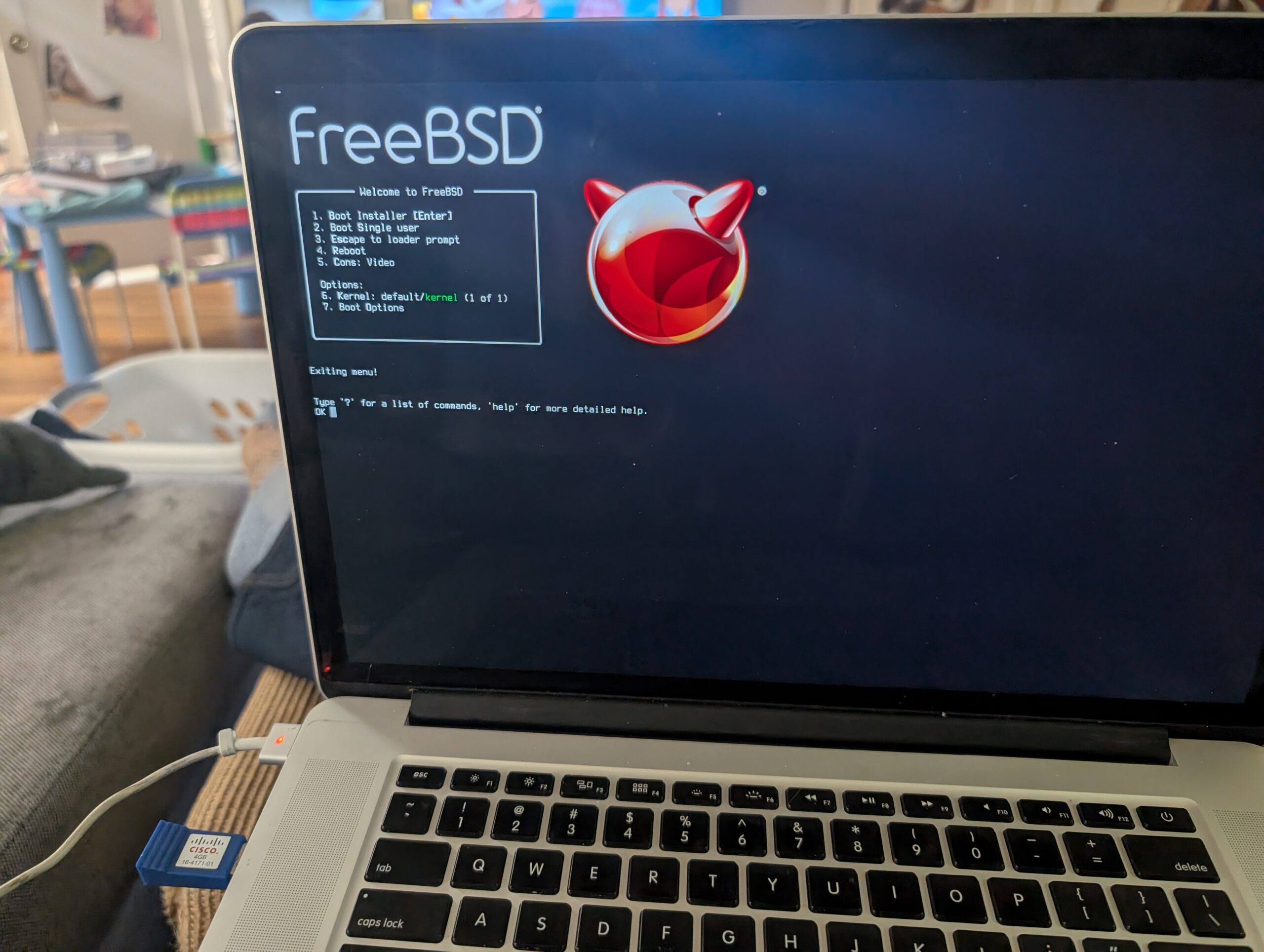
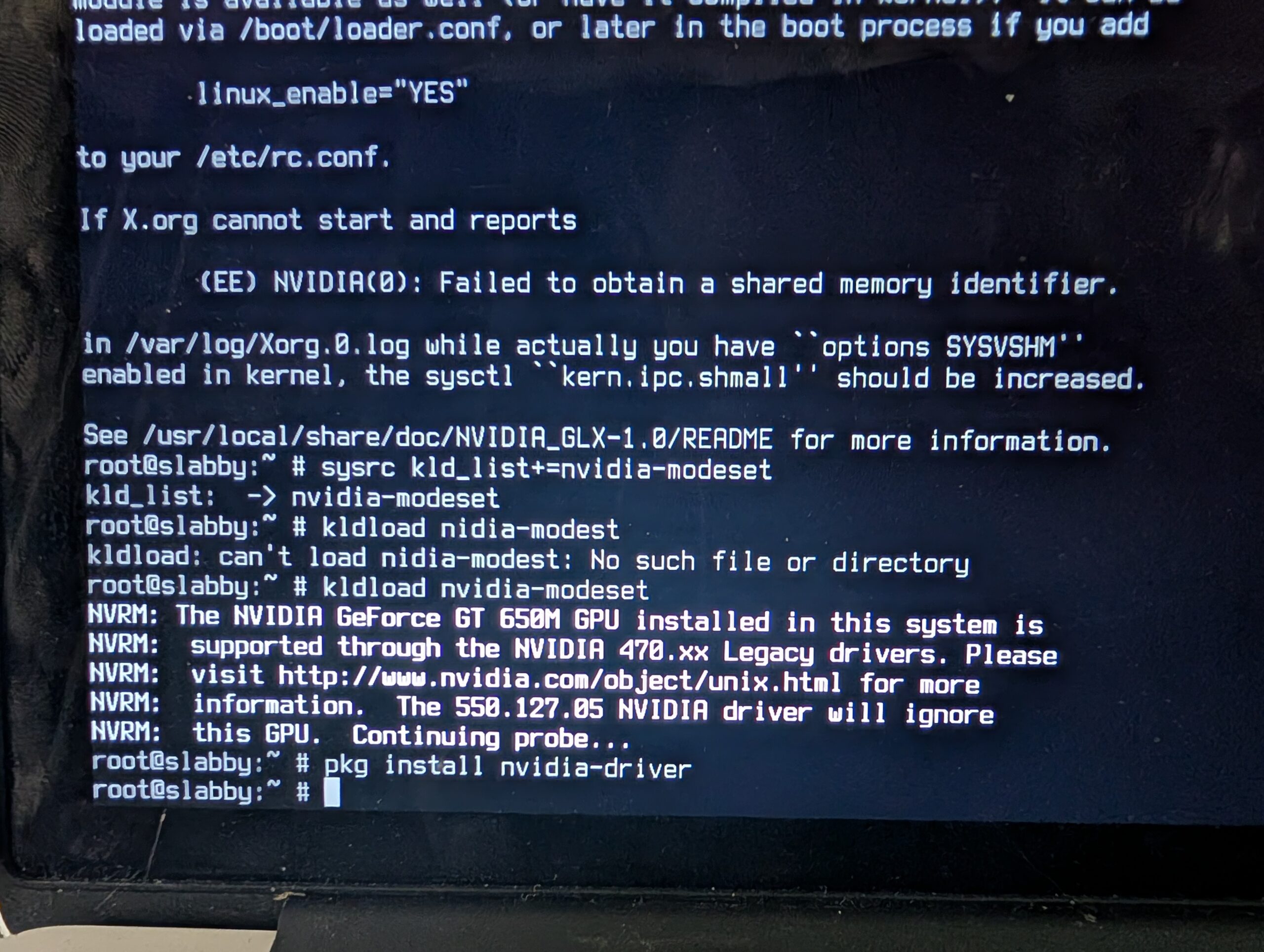
Yesterday, I installed FreeBSD.
You see, I picked up a very old 15″ MacBook Pro. Very Old like around a decade? I paid not more than $50. The battery officially “needs maintenance” but it is fine for web browsing or playing games while sitting on the sofa. Or it was, because Apple stopped supplying OS updates and then Google stopped supplying Chrome updates on the old MacOS and then Steam dropped support because it uses Chrome as an embedded browser. So, just slap Linux on there . . . but if we’re doing things in The Old Ways why not try FreeBSD?
FreeBSD was my first free Unix Operating System. I must have first used it in 1996? It is a great server OS, and made a fine desktop in the old days as well. Sometime in the aughts I transitioned to Ubuntu Linux, just because a more mainstream OS tends to have better support.
So, I busted out my old 4GB Cisco-branded USB key and tried it out. The crisp white fonts detailing the bootstrap felt comforting, probably from Old Days. The installer set up ZFS and added a user. From there I had to bust out a USB wifi dongle that had driver support. I worked my way through setting up nvidia drivers and X windows and KDE, and . . .
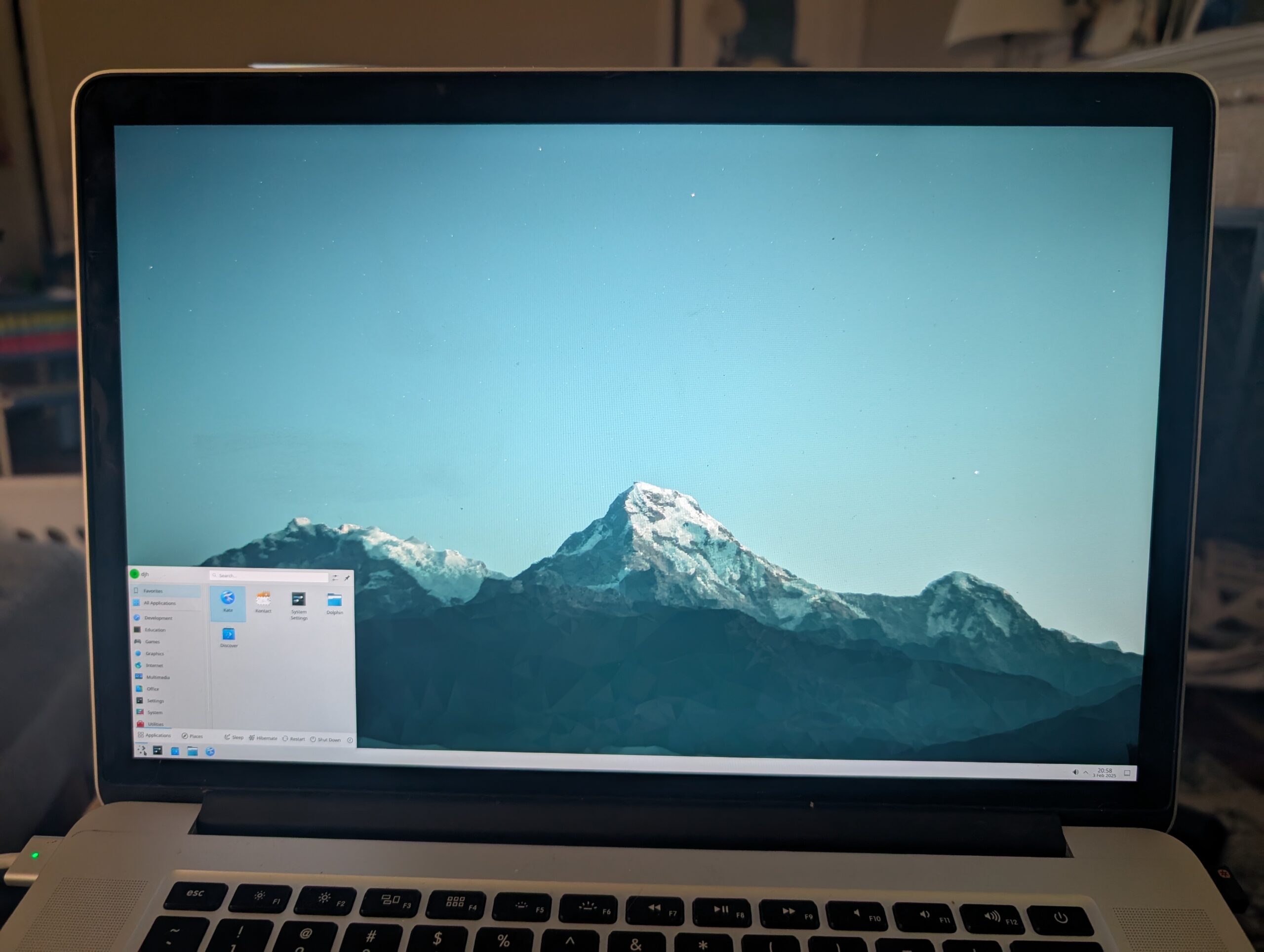
Once Plasma was running, it was easy enough to switch the display scaling to 150%. I was mostly home!
It was more effort just to get that far than I am used to with Linux. But, I enjoyed working my way through The Handbook like it was the late 90s all over again. That we watched an episode of “Babylon 5” while the system churned through a pile of Internet downloads really got that 90s vibe going. I couldn’t su. Then I recalled the wheel group, granted myself access, then installed sudo.
Alas, I got into trouble installing steam and google chrome because something was wrong with the Linux emulation required for both. And I had no clue how to get the internal wifi working. And the dongle was slow. Like 90s Internet. So, the next day, I busted out a 16GB Kingston USB device and brought kubuntu in. Quick work. ubuntu-drivers figured out how to activate the internal Broadcom wifi, though I had to manually sudo apt install nvidia-driver-470, but FreeBSD had given me the clue for that earlier:
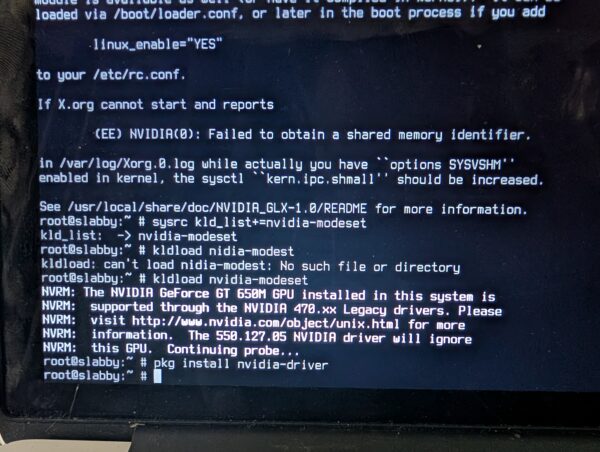
So, you could say, the visit to FreeBSD had been worth the trip.
2025-02-07 Friday
Yesterday I set out to catch up on bills. First order of business was to wipe the old phone and put it in the return mailer to get some trade-in credit from Google. I then noticed that my personal workstation was lagging on keyboard input. I tried a reboot. It got stuck at boot and soon after, stuck at BIOS. Fearing the worst, I started removing components: video card, M.2 daughter card, RAM … not until I disconnected the 2TB SATA drive did the system show signs of health. That was my “mass storage” where I keep the Photographs and Video. I dropped by Best Buy and grabbed a 2TB M.2 card . . . because there are actually slots on the motherboard, then I began the process of pulling the backups down from rsync.net.
My troubleshooting was backwards, you might figure: why not disconnect the hard drives first? Well, in my work life, I encounter bum hard drives often enough, and normally what happens is the system boots, there’s a delay in mounting the failed device, and then boot completes with an error message. Not booting at all . . . I guess this is a difference, probably, between a server-class motherboard and the thing I have in my home workstation which has blinky lights on it to appeal to gamers.
Didn’t get through any bills. And I had a Letter of Recommendation to write — my first, which I apologetically delayed. This morning, I ran up to The Office for All Hands, which got postponed . . . doing Something New is always somewhat intimidating. I was tempted to ask an AI for guidance but I’m a Gruff Old Man from the previous century, so I googled up “letter of recommendation” and got a nice template to follow. Combining that with a little more research and a little bit of writing talent and a desire to Come Through for Someone I wrote up what I felt was a pretty decent Letter of Recommendation and I hope my grateful friend finds some success in their endeavor.
Yay me for personal growth. Yay friend if they get the position! (Or even if they don’t. Personal Growth all around.)
2025-02-21 Friday
This obsession with the immediate “unburdening” of a thing you created is common in non-Japanese contexts, but I posit: The Japanese way is the correct way. Be an adult. Own your garbage. Garbage responsibility is something we’ve long since abdicated not only to faceless cans on street corners (or just all over the street, as seems to be the case in Manhattan or Paris), but also faceless developing countries around the world. Our oceans teem with the waste from generations of averted eyes. And I believe the two — local pathologies and attendant global pathologies — are not not connected.
The modern condition consists of a constant self-infantilization, of any number of “non-adulting” activities. The main being, of course, plugging into a dopamine casino right before going to sleep and right upon waking up. At least a morning cigarette habit in 1976 gave one time to look at the world in front of one’s eyes (and a gentle nicotine buzz). Other non-adulting activities include relinquishment of general attention, concentration, and critical thinking capabilities. The desire for deus ex machina style political intercession that belies the complexities of real-world systems. Easy answers, easy solutions to problems of unfathomable scale. Scientific retardation because it “feels” good. Deliverance — deliverance! — now, with as little effort as possible.
—Craig Mod, Ridgeline Transmission 203
Feedback Welcome
Link:
https://dannyman.toldme.com/2025/02/01/2025-01/
2024-05-18 Saturday
The Modern People came here from across the sea. Where they come from, they had been punished for what they believe. They say this land has been promised to them by God, and that they and their children will settle themselves all across the fertile parts of the land.
But we live here, as our ancestors did. What of us?
The Modern People say we should sign The Treaty. We will leave the places where we live now, the lands our ancestors knew, and we will be given an area of less fertile land. The Modern People say that we can live in our own ways and make our own laws in our own new land. They say they will protect our right to live there, just as they protect their right to live in their new land. They say that they will look after us. We will have enough food. They will share their Modern Medicine. If our children wish, they may even learn the Modern ways themselves.
Our children and their children will have less than their ancestors had. They will lose the lands our ancestors knew. They will need to rely on the The Modern People who took away the land in the first place. They will need to trust these Modern People not to take more. And more. And more.
But our people will still be alive. We will still be us. What choice do we have? If we do not sign The Treaty, there will be War. A War we will not survive.
2024-05-22 Wednesday
Lt. ________,
I am contacting you on the advice of ________. I was voicing concern regarding a neighbor who, as an act of protest against the bike lane in front of his house at ________, deliberately blocks the bike lane with his waste bins. Pickup day is Tuesday, so starting on Monday night, he’ll place the bins in the middle of the bike lane.

I see no harm if someone wants to protest the system. In this case, one house is forcing cyclists to merge into traffic on a bus route approaching an elementary school. There’s plenty of danger. Often, when I pass his house, I pull his bins to the curb as a courtesy.
Yesterday, he came out of his house and started yelling at me not to touch his bins. I explained that blocking the lane was dangerous and that he could be sued for injury. He yelled insults and vowed to move the bins back to the middle of the lane.
I called Public Safety, but they seemed a bit confused. The desk officer said it is illegal to park a car in a bike lane, but bins? I suggested that deliberately obstructing a roadway and endangering public safety might be a situation that could be resolved by a calm discussion with a uniformed officer. I later learned that CVC 21211(b) covers this situation.
This afternoon, around 3 pm, I saw that he was using yard work as a rationale to place his yard waste bin in the middle of the bike lane. I respect his tenacity. However, if someone from Public Safety could convince him to facilitate a safe roadway, we would all be better off.

Thank you for hearing me out. I can be reached at ________ if you have any questions.
-danny
2025-01-27 Monday
May was a long time ago. I am amazed at people who have the tenacity to stick with the same hobby year after year, decade after decade. I tend to rotate around my interests. What is new becomes old, then gets set aside, and later becomes new again. The Blog is a thing like that. Is it new again? We will see.
My informal goal for the year is to get an ADU built in the back yard. I spoke with cotta.ge last May, and they suggested a good price that I don’t entirely believe, but it gave us a little confidence.
But it is also a huge project: financing, architect, general contractor! And while the ADU rules in Sunnyvale are permissive, they also prohibit short-term rentals, so the initial concept of a guest suite for relatives and others doesn’t work. Also, our lot is on the small side, so we would likely want an attached ADU. At that point, the project becomes one of adding some space to the house while also building an ADU: the ADU gives us more flexibility in expanding our house in exchange for providing a badly-needed housing unit! Back-of-the-envelope is the high rents around here should cover the high construction costs around here, so with any luck we could add a home office / guest room for family “for free” in exchange for becoming reasonable landlords to hopefully reasonable tenants.
I need to sustain the energy to measure and sketch something out and pick up a book on home improvements. I have a vision I just need to find some follow through.
Oh, here’s a test, by the way … I upgraded this blog’s OS and PHP so now I wonder if I can upload pictures without first reducing their size.
Maximum upload file size: 2 MB.
Buhhh, will need to work on that, yet!
. . .
Fix DNS on an Ubuntu VM that was originally built in 2016 … edit /etc/php/8.3/apache2/php.ini and finally systemctl restart systemd-resolved and …

Infrastructure: always a work in progress!
Feedback Welcome
Link:
https://dannyman.toldme.com/2023/03/23/de-duplicating-files-with-jdupes/
Part of my day job involves looking at Nagios and checking up on systems that are filling their disks. I was looking at a system with a lot of large files, which are often duplicated, and I thought this would be less of an issue with de-duplication. There are filesystems that support de-duplication, but I recalled the fdupes command, a tool that “finds duplicate files” … if it can find duplicate files, could it perhaps hard-link the duplicates? The short answer is no.
But there is a fork of fdupes called jdupes, which supports de-duplication! I had to try it out.
It turns out your average Hadoop release ships with a healthy number of duplicate files, so I use that as a test corpus.
> du -hs hadoop-3.3.4
1.4G hadoop-3.3.4
> du -s hadoop-3.3.4
1413144 hadoop-3.3.4
> find hadoop-3.3.4 -type f | wc -l
22565
22,565 files in 1.4G, okay. What does jdupes think?
> jdupes -r hadoop-3.3.4 | head
Scanning: 22561 files, 2616 items (in 1 specified)
hadoop-3.3.4/NOTICE.txt
hadoop-3.3.4/share/hadoop/yarn/webapps/ui2/WEB-INF/classes/META-INF/NOTICE.txt
hadoop-3.3.4/libexec/hdfs-config.cmd
hadoop-3.3.4/libexec/mapred-config.cmd
hadoop-3.3.4/LICENSE.txt
hadoop-3.3.4/share/hadoop/yarn/webapps/ui2/WEB-INF/classes/META-INF/LICENSE.txt
hadoop-3.3.4/share/hadoop/common/lib/commons-net-3.6.jar
There are some duplicate files. Let’s take a look.
> diff hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 1 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 1 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/mapred-config.cmd
Look identical to me, yes.
> jdupes -r -m hadoop-3.3.4
Scanning: 22561 files, 2616 items (in 1 specified)
2859 duplicate files (in 167 sets), occupying 52 MB
Here, jdupes says it can consolidate the duplicate files and save 52 MB. That is not huge, but I am just testing.
> jdupes -r -L hadoop-3.3.4|head
Scanning: 22561 files, 2616 items (in 1 specified)
[SRC] hadoop-3.3.4/NOTICE.txt
----> hadoop-3.3.4/share/hadoop/yarn/webapps/ui2/WEB-INF/classes/META-INF/NOTICE.txt
[SRC] hadoop-3.3.4/libexec/hdfs-config.cmd
----> hadoop-3.3.4/libexec/mapred-config.cmd
[SRC] hadoop-3.3.4/LICENSE.txt
----> hadoop-3.3.4/share/hadoop/yarn/webapps/ui2/WEB-INF/classes/META-INF/LICENSE.txt
[SRC] hadoop-3.3.4/share/hadoop/common/lib/commons-net-3.6.jar
How about them duplicate files?
> diff hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/mapred-config.cmd
In the ls output, the “2” in the second column indicates the number of hard links to a file. Before we ran jdupes, each file only linked to itself. After, these two files link to the same spot on disk.
> du -s hadoop-3.3.4
1388980 hadoop-3.3.4
> find hadoop-3.3.4 -type f | wc -l
22566
The directory uses slightly less space, but the file count is the same!
But, be careful!
If you have a filesystem that de-duplicates data, that’s great. If you change the contents of a de-duplicated file, the filesystem will store the new data for the changed file and the old data for the unchanged file. If you de-duplicate with hard links and you edit a deduplicated file, you edit all the files that link to that location on disk. For example:
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/mapred-config.cmd
> echo foo >> hadoop-3.3.4/libexec/hdfs-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1644 Mar 23 16:16 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1644 Mar 23 16:16 hadoop-3.3.4/libexec/mapred-config.cmd
Both files are now 4 bytes longer! Maybe this is desired, but in plenty of cases, this could be a problem.
Of course, the nature of how you “edit” a file is very important. A file copy utility might replace the files, or it may re-write them in place. You need to experiment and check your documentation. Here is an experiment.
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1640 Mar 23 16:19 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1640 Mar 23 16:19 hadoop-3.3.4/libexec/mapred-config.cmd
> cp hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
cp: 'hadoop-3.3.4/libexec/hdfs-config.cmd' and 'hadoop-3.3.4/libexec/mapred-config.cmd' are the same file
The cp command is not having it. What if we replace one of the files?
> cp hadoop-3.3.4/libexec/mapred-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd.orig
> echo foo >> hadoop-3.3.4/libexec/hdfs-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1644 Mar 23 16:19 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1644 Mar 23 16:19 hadoop-3.3.4/libexec/mapred-config.cmd
> cp hadoop-3.3.4/libexec/mapred-config.cmd.orig hadoop-3.3.4/libexec/mapred-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1640 Mar 23 16:19 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1640 Mar 23 16:19 hadoop-3.3.4/libexec/mapred-config.cmd
When I run the cp command to replace one file, it replaces both files.
Back at work, I found I could save a lot of disk space on the system in question with jdupes -L, but I am also wary of unintended consequences of linking files together. If we pursue this strategy in the future, it will be with considerable caution.
Feedback Welcome
Link:
https://dannyman.toldme.com/2021/09/07/aqi-o-stat/
We bought our home in Northern California in 2012, which was great timing because that was about the last time after the mortgage crisis that we could reasonably afford a home, at a mere $605,000. At that time, the home had a floor/wall furnace from 1949 that had a hole that made it a carbon monoxide risk. We upgraded to central heating shortly after. Guys came out and ran ducts all over the attic and hooked them all up to an efficient gas furnace with an air filter. Topped it all off with a shiny Nest thermostat. It gets chilly out here on winter nights, and it used to be only a few days in the summer that anyone needed air conditioning, at which point you go to the office during the week or to the mall on the weekend.
In 2016 I added an air conditioner to the system. The local contractors seemed not quite comfortable with heat pumps, and the furnace was new, and we only run the air conditioner, well, now maybe a total of a few weeks each summer. A major construction project across the street involved asbestos mitigation, and we were having a baby, so the ability to shut the windows on bad days had some appeal. (I later gifted our old box unit AC to another expectant couple who had concerns with construction dust.)
Most of the time, we enjoy having windows open, day and night. Most of the time, our climate is blessedly mild—most of the time. The past few years have had a lot more smoke from all the fires in California. 2020 had an apocalyptic vibe when the plague was joined by a daytime sky turned orange. Shut the windows, run the AC, praise the air filter in the HVAC. For the Pandemic, I also set the air to circulate 15 minutes every hour during off-peak energy hours. (We’re on a Time-of-Use plan.) The idea is that if we had COVID-19 in our air, we would filter some of it out and help improve our odds.
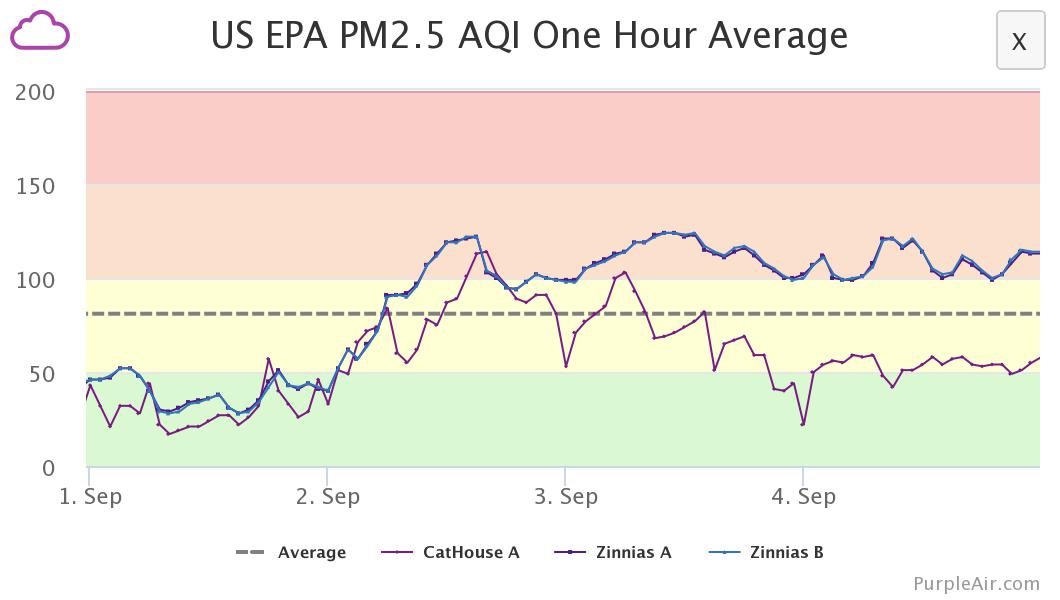
This year has been less awful. The winds have been mostly blowing the fire smoke from the hellscape experienced elsewhere in the West, away from the Bay Area. As a result, AQI has stayed mostly under 200. But as I had gotten back in the habit of checking purpleair.com to figure out if the windows need shut, I got curious to better understand the air quality inside our house, so I ponied up $200 for an indoor monitor. It has a bright LED that changes color based on what it measures, and the boys think that’s a pretty great night light.
My first revelation was that indoor AQI was spiking overnight, starting around midnight. Since I first installed it near the dishwasher, I figured that was the culprit. After a week of A/B testing, I had ruled out the dishwasher and figured out when the wife goes to bed, she likes to run a humidifier, and the water droplets in the air can look like pollution to a laser. Mystery solved!
The other thing I noticed while keeping an eye on purpleair.com to see if it was time to shut the windows is that our indoor AQI would tend to have a lower (better) score than outdoor sensors nearby. That’s good news. Zooming in, I could see a jaggy pattern where the AQI would drop when the furnace fan circulated our air through the MERV 16 filter in the attic, then it would spike back up. The upshot is that we could have open windows most of the time and cleaner air inside the house, but how to run the fan on an efficient schedule?
Well, it is tied to a thermostat … I could implement an “AQI-o-stat” with a Python script that scrapes the AQI reading and tells the Nest to run the fan. The script took about 3 hours to write. 10 minutes to scrape purpleair.com, 2.5 hours to figure out Google/Nest’s authentication API, and 20 minutes to figure out how to set the Nest fan. The authentication part took only 2.5 hours because Wouter Nieworth posted a bunch of helpful screenshots on his blog.
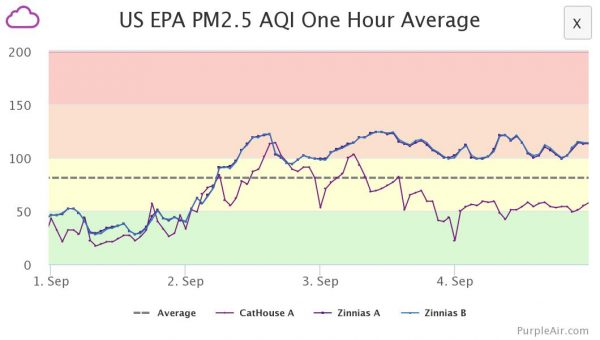
I implemented the “AQI-o-stat” on the afternoon of Sep 3, at which point CatHouse A now keeps AQI around 60 or below, while the neighboring Zinnias outdoor sensor reads in the low hundreds.
There was some tweaking, but I now have a Python script running out of cron that checks the indoor AQI, and if it is above 50, it triggers the timer on the fan. I started polling at 15-minute intervals but found 5-minute intervals made for a steadier outcome. The result is that we can leave the windows open, and the indoor air quality hovers around 60. One less thing to worry about. (There are plenty of things to worry about.) I have been thinking that, in the “New Normal” (which really means there is no “normal” because the climate systems have been thrown into turbulence) that having an air sensor as an input to your smart thermostat will probably just become a standard feature.
So, “hello” from the near future, I guess.
Feedback Welcome
Link:
https://dannyman.toldme.com/2018/08/29/fcc-should-expand-competition-for-internet-service-providers/
At the behest of my ISP, Sonic, I wrote a letter to the FCC, via https://savecompetition.com/:
Dear FCC,
I am a successful IT professional. I got my start in the 90s, answering phones at an independent ISP and getting folks online with their new modems. This was a great age when folks had a choice of any number of Internet SERVICE Providers who could help them get up and running on AT&T’s local telephone infrastructure.
To this very day, I use the DSL option available from the local Internet Service Provider (Sonic) over AT&T’s wires. I use this despite the fiber optic cable AT&T has hung on the pole in front of my house. Fiber would be so, so much faster, but I’m not going to pay for it until I have a CHOICE of providers, like Sonic, who has always been great about answering the phone and taking care of my Internet SERVICE needs.
Competitive services were the foundation of my career in IT. I believe they were a strong foundation to get Americans online in the first place. Competitive services are, in my opinion, REQUIRED, if you want to get Americans on to modern network technology today.
Feedback Welcome
Link:
https://dannyman.toldme.com/2018/06/06/why-hard-drives-get-slower-as-you-fill-them-up/
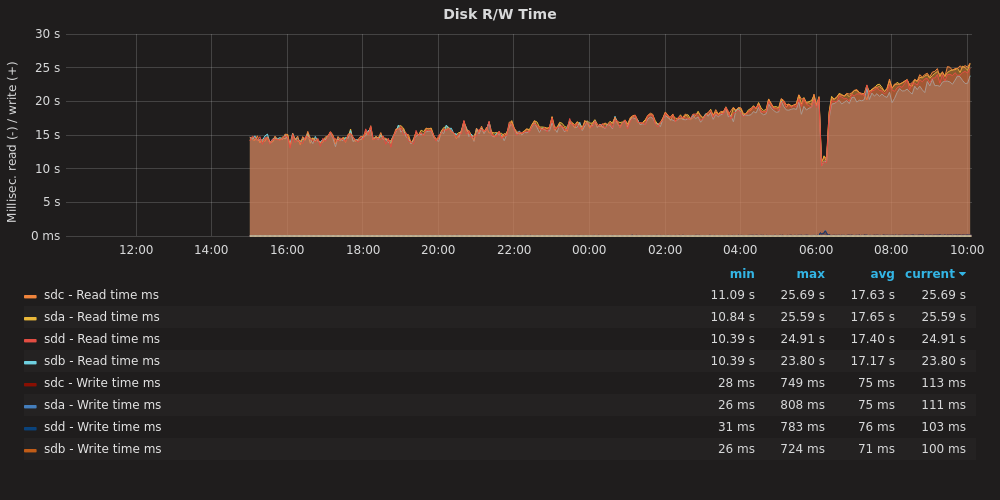
I built a new system (from old parts) yesterday. It is a RAID10 with 4x 8TB disks. While the system is up and running, it takes forever for mdadm to complete “building” the RAID. All the same, I got a little smile from this graph:
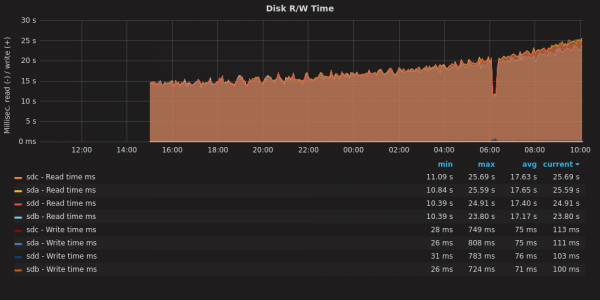
As the RAID assembles, the R/W operations take longer to complete.
The process should be about 20 hours total. As we get move through the job, the read-write operations take longer. Why? I have noticed this before. What happens here is that the disk rotates at a constant speed, but towards the rim you can fit a lot more data than towards the center. The speed with which you access data depends on whether you are talking to the core or to the rim of the magnetic platter.
What the computer does is it uses the fastest part of the disk first, and as the disk gets filled up, it uses the slower parts. With an operation like this that covers the entire disk, you start fast and get slower.
This is part of the reason that your hard drive slows down as it gets filled up: when your disk was new, the computer was using the fast-spinning outer rim. As that fills up, it has to read and write closer to the core. That takes longer. Another factor is that the data might be more segmented, packed into nooks and crannies where space is free, and your Operating System needs to seek those pieces out and assemble them. On a PC, the bigger culprit is probably that you have accumulated a bunch of extra running software that demands system resources.
Feedback Welcome
Link:
https://dannyman.toldme.com/2017/02/16/ganeti-exclusion-tags/
We have been using this great VM management software called Ganeti. It was developed at Google and I love it for the following reasons:
- It is at essence a collection of discrete, well-documented, command-line utilities
- It manages your VM infrastructure for you, in terms of what VMs to place where
- Killer feature: your VMs can all run as network-based RAID1s, the disk is mirrored on two nodes for rapid migration and failover without the need of an expensive, highly-available filer
- Good tech support via the mailing list
It is frustrating that relatively few people know about and use Ganeti, especially in the Silicon Valley.
Recently I had an itch to scratch. At the recent Ganeti Conference I heard tell that one could use tags to tell Ganeti to keep instances from running on the same node. This is another excellent feature: if you have two or more web servers, for example, you don’t want them to end up getting migrated to the same hardware.
Unfortunately, the documentation is a little obtuse, so I posted to the ganeti mailing list, and got the clues lined up.
First, you set a cluster exclusion tag, like so:
sudo gnt-cluster add-tags htools:iextags:role
This says “set up an exclusion tag, called role”
Then, when you create your instances, you add, for example: --tags role:prod-www
The instances created with the tag role:prod-www will be segregated onto different hardware nodes.
I did some testing to figure this out. First, as a control, create a bunch of small test instances:
sudo gnt-instance add ... ganeti-test0
sudo gnt-instance add ... ganeti-test1
sudo gnt-instance add ... ganeti-test2
sudo gnt-instance add ... ganeti-test3
sudo gnt-instance add ... ganeti-test4
Results:
$ sudo gnt-instance list | grep ganeti-test
ganeti-test0 kvm snf-image+default ganeti06-29 running 1.0G
ganeti-test1 kvm snf-image+default ganeti06-29 running 1.0G
ganeti-test2 kvm snf-image+default ganeti06-09 running 1.0G
ganeti-test3 kvm snf-image+default ganeti06-32 running 1.0G
ganeti-test4 kvm snf-image+default ganeti06-24 running 1.0G
As expected, some overlap in service nodes.
Next, delete the test instances, set a cluster exclusion tag for “role” and re-create the instances:
sudo gnt-cluster add-tags htools:iextags:role
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test0
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test1
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test2
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test3
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test4
Results?
$ sudo gnt-instance list | grep ganeti-test
ganeti-test0 kvm snf-image+default ganeti06-29 running 1.0G
ganeti-test1 kvm snf-image+default ganeti06-09 running 1.0G
ganeti-test2 kvm snf-image+default ganeti06-32 running 1.0G
ganeti-test3 kvm snf-image+default ganeti06-24 running 1.0G
ganeti-test4 kvm snf-image+default ganeti06-23 running 1.0G
Yay! The instances are allocated to five distinct nodes!
But am I sure I understand what I am doing? Nuke the instances and try another example: 2x “www” instances and 3x “app” instances:
sudo gnt-instance add ... --tags role:prod-www ganeti-test0
sudo gnt-instance add ... --tags role:prod-www ganeti-test1
sudo gnt-instance add ... --tags role:prod-app ganeti-test2
sudo gnt-instance add ... --tags role:prod-app ganeti-test3
sudo gnt-instance add ... --tags role:prod-app ganeti-test4
What do we get?
$ sudo gnt-instance list | grep ganeti-test
ganeti-test0 kvm snf-image+default ganeti06-29 running 1.0G # prod-www
ganeti-test1 kvm snf-image+default ganeti06-09 running 1.0G # prod-www
ganeti-test2 kvm snf-image+default ganeti06-29 running 1.0G # prod-app
ganeti-test3 kvm snf-image+default ganeti06-32 running 1.0G # prod-app
ganeti-test4 kvm snf-image+default ganeti06-24 running 1.0G # prod-app
Yes! The first two instances are allocated to different nodes, then when the tag changes to prod-app, ganeti goes back to ganeti06-29 to allocate an instance.
Feedback Welcome
Link:
https://dannyman.toldme.com/2017/01/27/duct-tape-ops/
Yesterday we tried out Slack’s new thread feature, and were left scratching our heads over the utility of that. Someone mused that Slack might be running out of features to implement, and I recalled Zawinski’s Law:
Every program attempts to expand until it can read mail. Those programs which cannot so expand are replaced by ones which can.
I think this is a tad ironic for Slack, given that some people believe that Slack makes email obsolete and useless. Anyway, I had ended up on Jamie Zawiski’s (jwz) Wikipedia entry and there was this comment about jwz’s law:
Eric Raymond comments that while this law goes against the minimalist philosophy of Unix (a set of “small, sharp tools”), it actually addresses the real need of end users to keep together tools for interrelated tasks, even though for a coder implementation of these tools are clearly independent jobs.
This led to The Duct Tape Programmer, which I’ll excerpt:
Sometimes you’re busy banging out the code, and someone starts rattling on about how if you use multi-threaded COM apartments, your app will be 34% sparklier, and it’s not even that hard, because he’s written a bunch of templates, and all you have to do is multiply-inherit from 17 of his templates, each taking an average of 4 arguments … your eyes are swimming.
And the duct-tape programmer is not afraid to say, “multiple inheritance sucks. Stop it. Just stop.”
You see, everybody else is too afraid of looking stupid … they sheepishly go along with whatever faddish programming craziness has come down from the architecture astronauts who speak at conferences and write books and articles and are so much smarter than us that they don’t realize that the stuff that they’re promoting is too hard for us.
“At the end of the day, ship the fucking thing! It’s great to rewrite your code and make it cleaner and by the third time it’ll actually be pretty. But that’s not the point—you’re not here to write code; you’re here to ship products.”
jwz wrote a response in his blog:
To the extent that he puts me up on a pedestal for merely being practical, that’s a pretty sad indictment of the state of the industry.
In a lot of the commentary surrounding his article elsewhere, I saw all the usual chestnuts being trotted out by people misunderstanding the context of our discussions: A) the incredible time pressure we were under and B) that it was 1994. People always want to get in fights over the specifics like “what’s wrong with templates?” without realizing the historical context. Guess what, you young punks, templates didn’t work in 1994.
As an older tech worker, I have found that I am more “fad resistant” than I was in my younger days. There’s older technology that may not be pretty but I know it works, and there’s new technology that may be shiny, but immature, and will take a lot of effort to get working. As time passes, shiny technology matures and becomes more practical to use.
(I am looking forward to trying “Kubernetes in a Can”)
Feedback Welcome
Link:
https://dannyman.toldme.com/2017/01/16/crontab-backtick-returncode-conditional-command/
A crontab entry I felt worth explanation, as it illustrates a few Unix concepts:
$ crontab -l
# m h dom mon dow command
*/5 8-18 * * mon-fri grep -q open /proc/acpi/button/lid/LID0/state && mkdir -p /home/djh/Dropbox/webcam/`date +%Y%m%d` && fswebcam -q -d /dev/video0 -r 1920x1080 /home/djh/Dropbox/webcam/%Y%m%d/%H%M.jpg ; file /home/djh/Dropbox/webcam/`date +%Y%m%d/%H%M`.jpg | grep -q 1920x1080 || fswebcam -q -d /dev/video1 -r 1920x1080 /home/djh/Dropbox/webcam/%Y%m%d/%H%M.jpg
That is a huge gob of text. Let me un-pack that into parts:
*/5 8-18 * * mon-fri
Run weekdays, 8AM to 6PM, every five minutes.
grep -q open /proc/acpi/button/lid/LID0/state &&
mkdir -p /home/djh/Dropbox/webcam/`date +%Y%m%d` &&
fswebcam -q -d /dev/video0 -r 1920x1080 /home/djh/Dropbox/webcam/%Y%m%d/%H%M.jpg
Check if the lid on the computer is open by looking for the word “open” in /proc/acpi/button/lid/LID0/state AND
(… if the lid is open) make a directory with today’s date AND
(… if the directory was made) take a timestamped snapshot from the web cam and put it in that folder.
Breaking it down a bit more:
grep -q means grep “quietly” … we don’t need to print that the lid is open, we care about the return code. Here is an illustration:
$ while true; do grep open /proc/acpi/button/lid/LID0/state ; echo $? ; sleep 1; done
state: open
0
state: open
0
# Lid gets shut
1
1
# Lid gets opened
state: open
0
state: open
0
The $? is the “return code” from the grep command. In shell, zero means true and non-zero means false, that allows us to conveniently construct conditional commands. Like so:
$ while true; do grep -q open /proc/acpi/button/lid/LID0/state && echo "open lid: take a picture" || echo "shut lid: take no picture" ; sleep 1; done
open lid: take a picture
open lid: take a picture
shut lid: take no picture
shut lid: take no picture
open lid: take a picture
open lid: take a picture
There is some juju in making the directory:
mkdir -p /home/djh/Dropbox/webcam/`date +%Y%m%d`
First is the -p flag. That would make every part of the path, if needed (Dropbox .. webcam ..) but it also makes mkdir chill if the directory already exist:
$ mkdir /tmp ; echo $?
mkdir: cannot create directory ‘/tmp’: File exists
1
$ mkdir -p /tmp ; echo $?
0
Then there is the backtick substitition. The date command can format output (read man date and man strftime …) You can use the backtick substitution to stuff the output of one command into the input of another command.
$ date +%A
Monday
$ echo "Today is `date +%A`"
Today is Monday
Once again, from the top:
grep -q open /proc/acpi/button/lid/LID0/state &&
mkdir -p /home/djh/Dropbox/webcam/`date +%Y%m%d` &&
fswebcam -q -d /dev/video0 -r 1920x1080 /home/djh/Dropbox/webcam/%Y%m%d/%H%M.jpg ;
file /home/djh/Dropbox/webcam/`date +%Y%m%d/%H%M`.jpg | grep -q 1920x1080 ||
fswebcam -q -d /dev/video1 -r 1920x1080 /home/djh/Dropbox/webcam/%Y%m%d/%H%M.jpg
Here is where it gets involved. There are two cameras on this mobile workstation. One is the internal camera, which can do 720 pixels, and there is an external camera, which can do 1080. I want to use the external camera, but there is no consistency for the device name. (The external device is video0 if it is present at boot, else it is video1.)
Originally, I wanted to do like so:
fswebcam -q -d /dev/video0 -r 1920x1080 || fswebcam -q -d /dev/video1 -r 1920x1080
Unfortunately, fswebcam is a real trooper: if it can not take a picture at 1920×1080, it will take what picture it can and output that. This is why the whole cron entry reads as:
Check if the lid on the computer is open AND
(… if the lid is open) make a directory with today’s date AND
(… if the directory was made) take a timestamped snapshot from web cam 0
Check if the timestamped snapshot is 1920×1080 ELSE
(… if the snapshot is not 1920×1080) take a timestamped snapshot from web cam 1

Sample output from webcam. Happy MLK Day.
Why am I taking these snapshots? I do not really know what I might do with them until I have them. Modern algorithms could analyze “time spent at workstation” and give feedback on posture, maybe identify “mood” and correlate that over time … we’ll see.
OR not.
Feedback Welcome
Link:
https://dannyman.toldme.com/2016/12/29/it-wasnt-that-bad/
Friend: Dang it Apple my iPhone upgrade bricked the phone and I had to reinstall from scratch. This is a _really_ bad user experience.
Me: If you can re-install the software, the phone isn’t actually “bricked” …
Friend: I had to do a factory restore through iTunes.
Me: That’s not bricked that’s just extremely awful software.
(Someone else mentions Windows.)
Me: Never had this problem with an Android device. ;)
Friend: With Android phones you are constantly waiting on the carriers or handset makers for updates.
Me: That is why I buy my phones from Google.
Friend: Pixel looks enticing, I still like iPhone better. I am a firm believer that people stick with what they know, and you are unlikely to sway them if it works for them.
Me: Yeah just because you have to reinstall your whole phone from scratch doesn’t make it a bad experience.
Feedback Welcome
Link:
https://dannyman.toldme.com/2016/08/24/vms-vs-containers/
I’ve been a SysAdmin for … since the last millennium. Long enough to see certain fads come and go and come again. There was a time when folks got keen on the advantages of chroot jails, but that time faded, then resurged in the form of containers! All the rage!
My own bias is that bare metal systems and VMs are what I am used to: a Unix SysAdmin knows how to manage systems! The advantages and desire for more contained environments seems to better suit certain types of programmers, and I suspect that the desire for chroot-jail-virtualenv-containers may be a reflection of programming trends.
On the one hand, you’ve got say C and Java … write, compile, deploy. You can statically link C code and put your Java all in a big jar, and then to run it on a server you’ll need say a particular kernel version, or a particular version of Java, and some light scaffolding to configure, start/stop and log. You can just write up a little README and hand that stuff off to the Ops team and they’ll figure out the mysterious stuff like chmod and the production database password. (And the load balancer config..eek!)
On the other hand, if you’re hacking away in an interpreted language: say Python or R, you’ve got a growing wad of dependencies, and eventually you’ll get to a point where you need the older version of one dependency and a bleeding-edge version of another and keeping track of those dependencies and convincing the OS to furnish them all for you … what comes in handy is if you can just wad up a giant tarball of all your stuff and run it in a little “isolated” environment. You don’t really want to get Ops involved because they may laugh at you or run in terror … instead you can just shove the whole thing in a container, run that thing in the cloud, and now without even ever having to understand esoteric stuff like chmod you are now DevOps!
(Woah: Job Security!!)
From my perspective, containers start as a way to deploy software. Nowadays there’s a bunch of scaffolding for containers to be a way to deploy and manage a service stack. I haven’t dealt with either case, and my incumbent philosophy tends to be “well, we already have these other tools” …
Container Architecture is basically just Legos mixed with Minecraft (CC: Wikipedia)
Anyway, as a Service Provider (… I know “DevOps” is meant to get away from that ugly idea that Ops is a service provider …) I figure if containers help us ship the code, we’ll get us some containers, and if we want orchestration capabilities … well, we have what we have now and we can look at bringing up other new stuff if it will serve us better.
ASIDE: One thing that has put me off containers thus far is not so much that they’re reinventing the wheel, so much that I went to a DevOps conference a few years back and it seemed every single talk was about how we have been delivered from the evil sinful ways of physical computers and VMs and the tyranny of package managers and chmod and load balancers and we have found the Good News that we can build this stuff all over in a new image and it will be called Docker or Mesos or Kubernetes but careful the API changed in the last version but have you heard we have a thing called etcd which is a special thing to manage your config files because nobody has ever figured out an effective way to … honestly I don’t know for etcd one way or another: it was just the glazed, fervent stare in the eyes of the guy who was explaining to me the virtues of etcd …
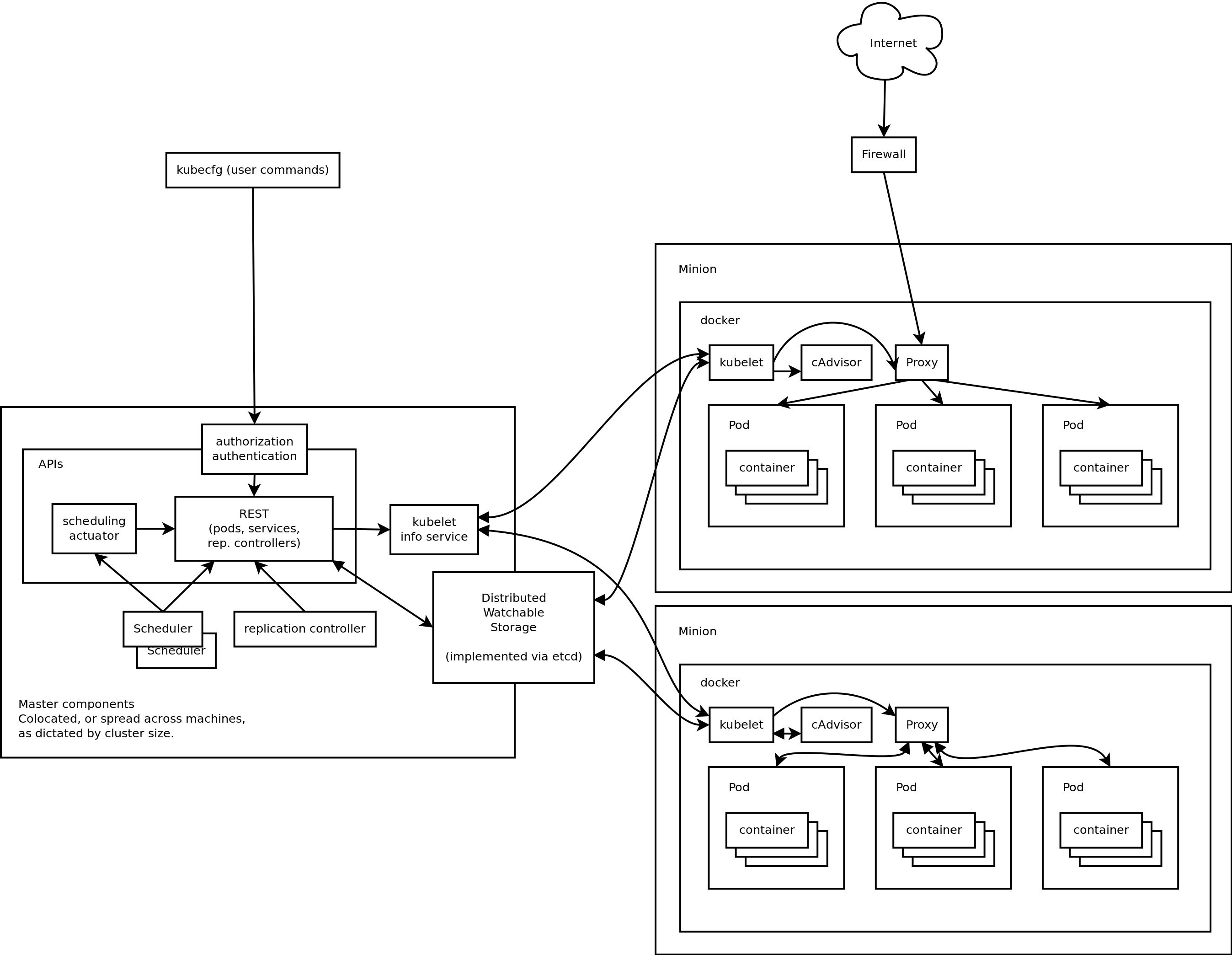
It turns out it is not just me who is a curmudgeonly contrarian: a lot of people are freaked out by the True Believers. But that needn’t keep us from deploying useful tools, and my colleague reports that Kubernetes for containers seems awfully similar to the Ganeti we are already running for VMs, so let us bootstrap some infrastructure and provide some potentially useful services to the development team, shall we?
Feedback Welcome
Link:
https://dannyman.toldme.com/2016/07/19/testimonial-sslmate/
I recently started using sslmate to manage SSL certificates. SSL is one of those complicated things you deal with rarely so it has historically been a pain in the neck.
But sslmate makes it all easy … you install the sslmate command and can generate, sign, and install certificates from the command-line. You then have to check your email when getting a signed cert to verify … and you’re good.
The certificates auto-renew annually, assuming you click the email. I did this for an important cert yesterday. Another thing you do (sslmate walks you through all these details) is set up a cron.
This morning at 6:25am the cron got run on our servers … with minimal intervention (I had to click a confirmation link on an email yesterday) our web servers are now running on renewed certs …. one less pain in the neck.
So … next time you have to deal with SSL I would say “go to sslmate.com and follow the instructions and you’ll be in a happy place.”
Feedback Welcome
Older Stuff »
Site Archive





{kind=link}
{kind=link}