Link:
https://dannyman.toldme.com/2025/03/04/2025-02/
2025-02-04 Tuesday
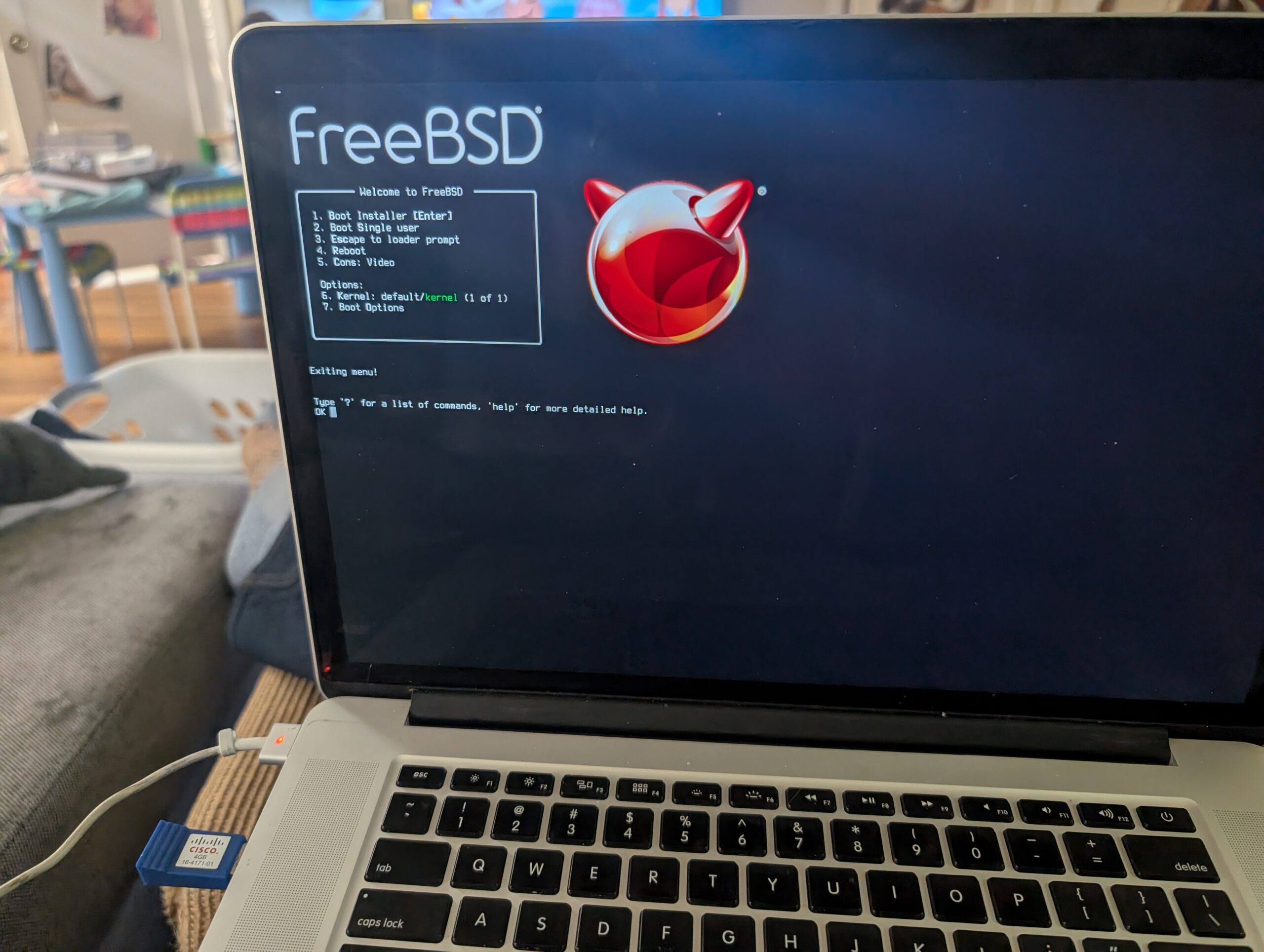
Yesterday, I installed FreeBSD.
You see, I picked up a very old 15″ MacBook Pro. Very Old like around a decade? I paid not more than $50. The battery officially “needs maintenance” but it is fine for web browsing or playing games while sitting on the sofa. Or it was, because Apple stopped supplying OS updates and then Google stopped supplying Chrome updates on the old MacOS and then Steam dropped support because it uses Chrome as an embedded browser. So, just slap Linux on there . . . but if we’re doing things in The Old Ways why not try FreeBSD?
FreeBSD was my first free Unix Operating System. I must have first used it in 1996? It is a great server OS, and made a fine desktop in the old days as well. Sometime in the aughts I transitioned to Ubuntu Linux, just because a more mainstream OS tends to have better support.
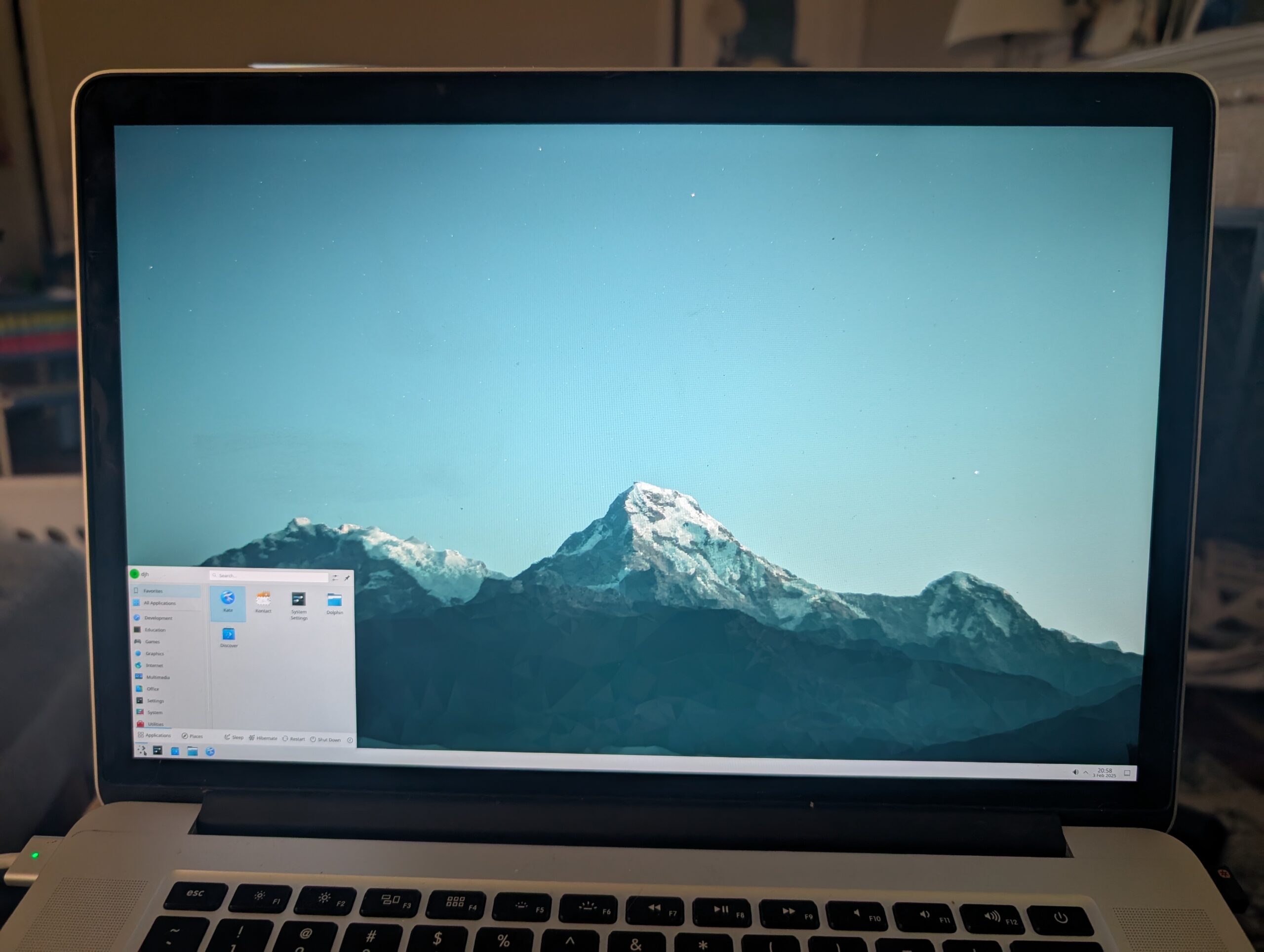
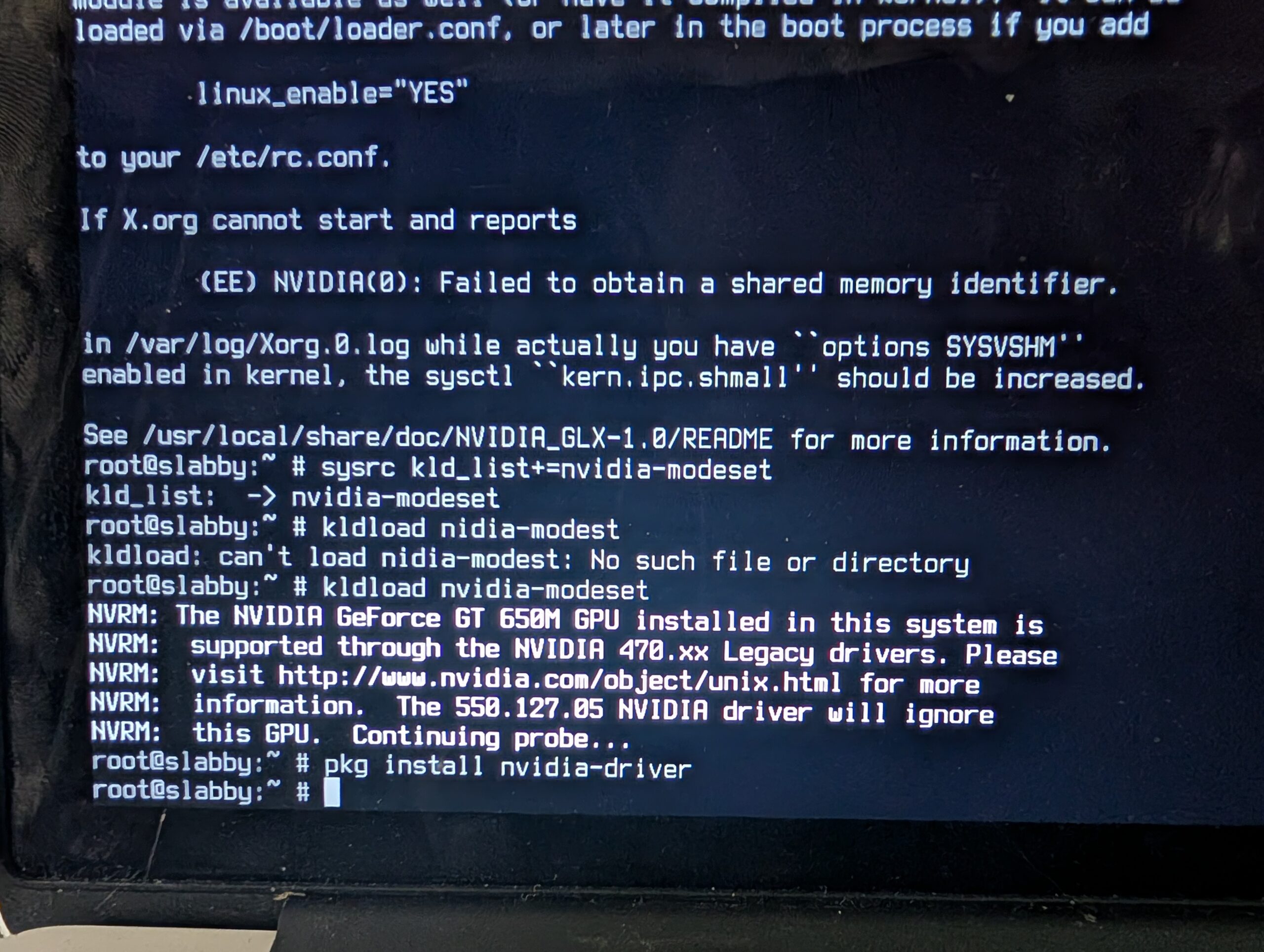
So, I busted out my old 4GB Cisco-branded USB key and tried it out. The crisp white fonts detailing the bootstrap felt comforting, probably from Old Days. The installer set up ZFS and added a user. From there I had to bust out a USB wifi dongle that had driver support. I worked my way through setting up nvidia drivers and X windows and KDE, and . . .
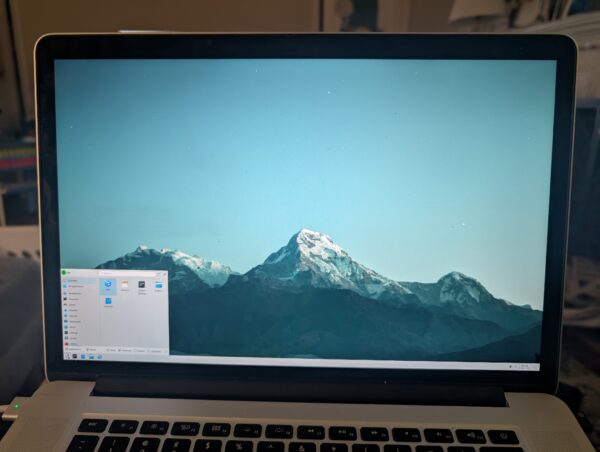
Once Plasma was running, it was easy enough to switch the display scaling to 150%. I was mostly home!
It was more effort just to get that far than I am used to with Linux. But, I enjoyed working my way through The Handbook like it was the late 90s all over again. That we watched an episode of “Babylon 5” while the system churned through a pile of Internet downloads really got that 90s vibe going. I couldn’t su. Then I recalled the wheel group, granted myself access, then installed sudo.
Alas, I got into trouble installing steam and google chrome because something was wrong with the Linux emulation required for both. And I had no clue how to get the internal wifi working. And the dongle was slow. Like 90s Internet. So, the next day, I busted out a 16GB Kingston USB device and brought kubuntu in. Quick work. ubuntu-drivers figured out how to activate the internal Broadcom wifi, though I had to manually sudo apt install nvidia-driver-470, but FreeBSD had given me the clue for that earlier:
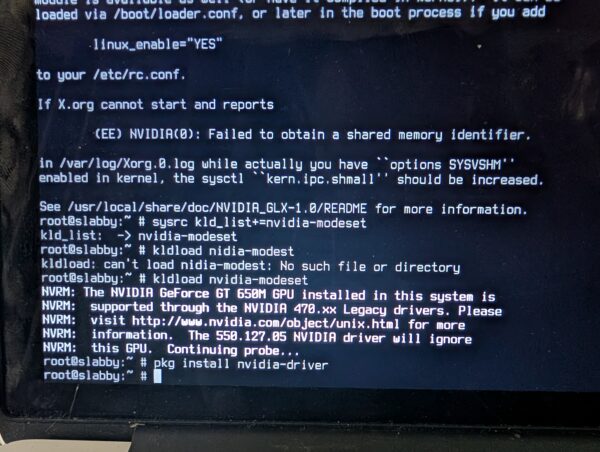
So, you could say, the visit to FreeBSD had been worth the trip.
2025-02-07 Friday
Yesterday I set out to catch up on bills. First order of business was to wipe the old phone and put it in the return mailer to get some trade-in credit from Google. I then noticed that my personal workstation was lagging on keyboard input. I tried a reboot. It got stuck at boot and soon after, stuck at BIOS. Fearing the worst, I started removing components: video card, M.2 daughter card, RAM … not until I disconnected the 2TB SATA drive did the system show signs of health. That was my “mass storage” where I keep the Photographs and Video. I dropped by Best Buy and grabbed a 2TB M.2 card . . . because there are actually slots on the motherboard, then I began the process of pulling the backups down from rsync.net.
My troubleshooting was backwards, you might figure: why not disconnect the hard drives first? Well, in my work life, I encounter bum hard drives often enough, and normally what happens is the system boots, there’s a delay in mounting the failed device, and then boot completes with an error message. Not booting at all . . . I guess this is a difference, probably, between a server-class motherboard and the thing I have in my home workstation which has blinky lights on it to appeal to gamers.
Didn’t get through any bills. And I had a Letter of Recommendation to write — my first, which I apologetically delayed. This morning, I ran up to The Office for All Hands, which got postponed . . . doing Something New is always somewhat intimidating. I was tempted to ask an AI for guidance but I’m a Gruff Old Man from the previous century, so I googled up “letter of recommendation” and got a nice template to follow. Combining that with a little more research and a little bit of writing talent and a desire to Come Through for Someone I wrote up what I felt was a pretty decent Letter of Recommendation and I hope my grateful friend finds some success in their endeavor.
Yay me for personal growth. Yay friend if they get the position! (Or even if they don’t. Personal Growth all around.)
2025-02-21 Friday
This obsession with the immediate “unburdening” of a thing you created is common in non-Japanese contexts, but I posit: The Japanese way is the correct way. Be an adult. Own your garbage. Garbage responsibility is something we’ve long since abdicated not only to faceless cans on street corners (or just all over the street, as seems to be the case in Manhattan or Paris), but also faceless developing countries around the world. Our oceans teem with the waste from generations of averted eyes. And I believe the two — local pathologies and attendant global pathologies — are not not connected.
The modern condition consists of a constant self-infantilization, of any number of “non-adulting” activities. The main being, of course, plugging into a dopamine casino right before going to sleep and right upon waking up. At least a morning cigarette habit in 1976 gave one time to look at the world in front of one’s eyes (and a gentle nicotine buzz). Other non-adulting activities include relinquishment of general attention, concentration, and critical thinking capabilities. The desire for deus ex machina style political intercession that belies the complexities of real-world systems. Easy answers, easy solutions to problems of unfathomable scale. Scientific retardation because it “feels” good. Deliverance — deliverance! — now, with as little effort as possible.
—Craig Mod, Ridgeline Transmission 203
Feedback Welcome
Link:
https://dannyman.toldme.com/2025/02/01/2025-01/
2024-05-18 Saturday
The Modern People came here from across the sea. Where they come from, they had been punished for what they believe. They say this land has been promised to them by God, and that they and their children will settle themselves all across the fertile parts of the land.
But we live here, as our ancestors did. What of us?
The Modern People say we should sign The Treaty. We will leave the places where we live now, the lands our ancestors knew, and we will be given an area of less fertile land. The Modern People say that we can live in our own ways and make our own laws in our own new land. They say they will protect our right to live there, just as they protect their right to live in their new land. They say that they will look after us. We will have enough food. They will share their Modern Medicine. If our children wish, they may even learn the Modern ways themselves.
Our children and their children will have less than their ancestors had. They will lose the lands our ancestors knew. They will need to rely on the The Modern People who took away the land in the first place. They will need to trust these Modern People not to take more. And more. And more.
But our people will still be alive. We will still be us. What choice do we have? If we do not sign The Treaty, there will be War. A War we will not survive.
2024-05-22 Wednesday
Lt. ________,
I am contacting you on the advice of ________. I was voicing concern regarding a neighbor who, as an act of protest against the bike lane in front of his house at ________, deliberately blocks the bike lane with his waste bins. Pickup day is Tuesday, so starting on Monday night, he’ll place the bins in the middle of the bike lane.

I see no harm if someone wants to protest the system. In this case, one house is forcing cyclists to merge into traffic on a bus route approaching an elementary school. There’s plenty of danger. Often, when I pass his house, I pull his bins to the curb as a courtesy.
Yesterday, he came out of his house and started yelling at me not to touch his bins. I explained that blocking the lane was dangerous and that he could be sued for injury. He yelled insults and vowed to move the bins back to the middle of the lane.
I called Public Safety, but they seemed a bit confused. The desk officer said it is illegal to park a car in a bike lane, but bins? I suggested that deliberately obstructing a roadway and endangering public safety might be a situation that could be resolved by a calm discussion with a uniformed officer. I later learned that CVC 21211(b) covers this situation.
This afternoon, around 3 pm, I saw that he was using yard work as a rationale to place his yard waste bin in the middle of the bike lane. I respect his tenacity. However, if someone from Public Safety could convince him to facilitate a safe roadway, we would all be better off.

Thank you for hearing me out. I can be reached at ________ if you have any questions.
-danny
2025-01-27 Monday
May was a long time ago. I am amazed at people who have the tenacity to stick with the same hobby year after year, decade after decade. I tend to rotate around my interests. What is new becomes old, then gets set aside, and later becomes new again. The Blog is a thing like that. Is it new again? We will see.
My informal goal for the year is to get an ADU built in the back yard. I spoke with cotta.ge last May, and they suggested a good price that I don’t entirely believe, but it gave us a little confidence.
But it is also a huge project: financing, architect, general contractor! And while the ADU rules in Sunnyvale are permissive, they also prohibit short-term rentals, so the initial concept of a guest suite for relatives and others doesn’t work. Also, our lot is on the small side, so we would likely want an attached ADU. At that point, the project becomes one of adding some space to the house while also building an ADU: the ADU gives us more flexibility in expanding our house in exchange for providing a badly-needed housing unit! Back-of-the-envelope is the high rents around here should cover the high construction costs around here, so with any luck we could add a home office / guest room for family “for free” in exchange for becoming reasonable landlords to hopefully reasonable tenants.
I need to sustain the energy to measure and sketch something out and pick up a book on home improvements. I have a vision I just need to find some follow through.
Oh, here’s a test, by the way … I upgraded this blog’s OS and PHP so now I wonder if I can upload pictures without first reducing their size.
Maximum upload file size: 2 MB.
Buhhh, will need to work on that, yet!
. . .
Fix DNS on an Ubuntu VM that was originally built in 2016 … edit /etc/php/8.3/apache2/php.ini and finally systemctl restart systemd-resolved and …

Infrastructure: always a work in progress!
Feedback Welcome
Link:
https://dannyman.toldme.com/2023/03/23/de-duplicating-files-with-jdupes/
Part of my day job involves looking at Nagios and checking up on systems that are filling their disks. I was looking at a system with a lot of large files, which are often duplicated, and I thought this would be less of an issue with de-duplication. There are filesystems that support de-duplication, but I recalled the fdupes command, a tool that “finds duplicate files” … if it can find duplicate files, could it perhaps hard-link the duplicates? The short answer is no.
But there is a fork of fdupes called jdupes, which supports de-duplication! I had to try it out.
It turns out your average Hadoop release ships with a healthy number of duplicate files, so I use that as a test corpus.
> du -hs hadoop-3.3.4
1.4G hadoop-3.3.4
> du -s hadoop-3.3.4
1413144 hadoop-3.3.4
> find hadoop-3.3.4 -type f | wc -l
22565
22,565 files in 1.4G, okay. What does jdupes think?
> jdupes -r hadoop-3.3.4 | head
Scanning: 22561 files, 2616 items (in 1 specified)
hadoop-3.3.4/NOTICE.txt
hadoop-3.3.4/share/hadoop/yarn/webapps/ui2/WEB-INF/classes/META-INF/NOTICE.txt
hadoop-3.3.4/libexec/hdfs-config.cmd
hadoop-3.3.4/libexec/mapred-config.cmd
hadoop-3.3.4/LICENSE.txt
hadoop-3.3.4/share/hadoop/yarn/webapps/ui2/WEB-INF/classes/META-INF/LICENSE.txt
hadoop-3.3.4/share/hadoop/common/lib/commons-net-3.6.jar
There are some duplicate files. Let’s take a look.
> diff hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 1 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 1 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/mapred-config.cmd
Look identical to me, yes.
> jdupes -r -m hadoop-3.3.4
Scanning: 22561 files, 2616 items (in 1 specified)
2859 duplicate files (in 167 sets), occupying 52 MB
Here, jdupes says it can consolidate the duplicate files and save 52 MB. That is not huge, but I am just testing.
> jdupes -r -L hadoop-3.3.4|head
Scanning: 22561 files, 2616 items (in 1 specified)
[SRC] hadoop-3.3.4/NOTICE.txt
----> hadoop-3.3.4/share/hadoop/yarn/webapps/ui2/WEB-INF/classes/META-INF/NOTICE.txt
[SRC] hadoop-3.3.4/libexec/hdfs-config.cmd
----> hadoop-3.3.4/libexec/mapred-config.cmd
[SRC] hadoop-3.3.4/LICENSE.txt
----> hadoop-3.3.4/share/hadoop/yarn/webapps/ui2/WEB-INF/classes/META-INF/LICENSE.txt
[SRC] hadoop-3.3.4/share/hadoop/common/lib/commons-net-3.6.jar
How about them duplicate files?
> diff hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/mapred-config.cmd
In the ls output, the “2” in the second column indicates the number of hard links to a file. Before we ran jdupes, each file only linked to itself. After, these two files link to the same spot on disk.
> du -s hadoop-3.3.4
1388980 hadoop-3.3.4
> find hadoop-3.3.4 -type f | wc -l
22566
The directory uses slightly less space, but the file count is the same!
But, be careful!
If you have a filesystem that de-duplicates data, that’s great. If you change the contents of a de-duplicated file, the filesystem will store the new data for the changed file and the old data for the unchanged file. If you de-duplicate with hard links and you edit a deduplicated file, you edit all the files that link to that location on disk. For example:
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1640 Jul 29 2022 hadoop-3.3.4/libexec/mapred-config.cmd
> echo foo >> hadoop-3.3.4/libexec/hdfs-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1644 Mar 23 16:16 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1644 Mar 23 16:16 hadoop-3.3.4/libexec/mapred-config.cmd
Both files are now 4 bytes longer! Maybe this is desired, but in plenty of cases, this could be a problem.
Of course, the nature of how you “edit” a file is very important. A file copy utility might replace the files, or it may re-write them in place. You need to experiment and check your documentation. Here is an experiment.
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1640 Mar 23 16:19 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1640 Mar 23 16:19 hadoop-3.3.4/libexec/mapred-config.cmd
> cp hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
cp: 'hadoop-3.3.4/libexec/hdfs-config.cmd' and 'hadoop-3.3.4/libexec/mapred-config.cmd' are the same file
The cp command is not having it. What if we replace one of the files?
> cp hadoop-3.3.4/libexec/mapred-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd.orig
> echo foo >> hadoop-3.3.4/libexec/hdfs-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1644 Mar 23 16:19 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1644 Mar 23 16:19 hadoop-3.3.4/libexec/mapred-config.cmd
> cp hadoop-3.3.4/libexec/mapred-config.cmd.orig hadoop-3.3.4/libexec/mapred-config.cmd
> ls -l hadoop-3.3.4/libexec/hdfs-config.cmd hadoop-3.3.4/libexec/mapred-config.cmd
-rwxr-xr-x 2 djh djh 1640 Mar 23 16:19 hadoop-3.3.4/libexec/hdfs-config.cmd
-rwxr-xr-x 2 djh djh 1640 Mar 23 16:19 hadoop-3.3.4/libexec/mapred-config.cmd
When I run the cp command to replace one file, it replaces both files.
Back at work, I found I could save a lot of disk space on the system in question with jdupes -L, but I am also wary of unintended consequences of linking files together. If we pursue this strategy in the future, it will be with considerable caution.
Feedback Welcome
Link:
https://dannyman.toldme.com/2018/06/06/why-hard-drives-get-slower-as-you-fill-them-up/
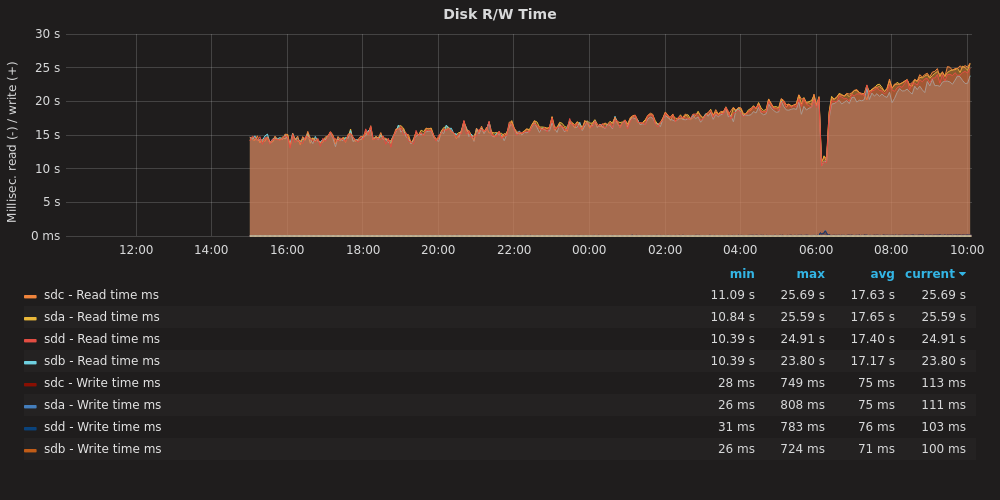
I built a new system (from old parts) yesterday. It is a RAID10 with 4x 8TB disks. While the system is up and running, it takes forever for mdadm to complete “building” the RAID. All the same, I got a little smile from this graph:
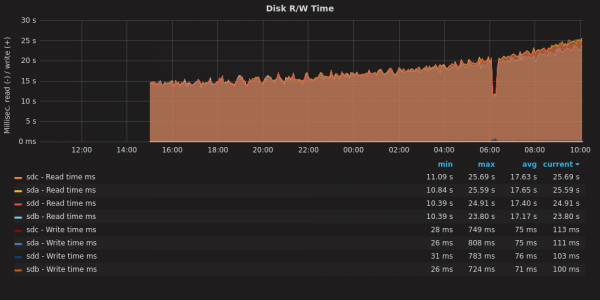
As the RAID assembles, the R/W operations take longer to complete.
The process should be about 20 hours total. As we get move through the job, the read-write operations take longer. Why? I have noticed this before. What happens here is that the disk rotates at a constant speed, but towards the rim you can fit a lot more data than towards the center. The speed with which you access data depends on whether you are talking to the core or to the rim of the magnetic platter.
What the computer does is it uses the fastest part of the disk first, and as the disk gets filled up, it uses the slower parts. With an operation like this that covers the entire disk, you start fast and get slower.
This is part of the reason that your hard drive slows down as it gets filled up: when your disk was new, the computer was using the fast-spinning outer rim. As that fills up, it has to read and write closer to the core. That takes longer. Another factor is that the data might be more segmented, packed into nooks and crannies where space is free, and your Operating System needs to seek those pieces out and assemble them. On a PC, the bigger culprit is probably that you have accumulated a bunch of extra running software that demands system resources.
Feedback Welcome
Link:
https://dannyman.toldme.com/2017/02/16/ganeti-exclusion-tags/
We have been using this great VM management software called Ganeti. It was developed at Google and I love it for the following reasons:
- It is at essence a collection of discrete, well-documented, command-line utilities
- It manages your VM infrastructure for you, in terms of what VMs to place where
- Killer feature: your VMs can all run as network-based RAID1s, the disk is mirrored on two nodes for rapid migration and failover without the need of an expensive, highly-available filer
- Good tech support via the mailing list
It is frustrating that relatively few people know about and use Ganeti, especially in the Silicon Valley.
Recently I had an itch to scratch. At the recent Ganeti Conference I heard tell that one could use tags to tell Ganeti to keep instances from running on the same node. This is another excellent feature: if you have two or more web servers, for example, you don’t want them to end up getting migrated to the same hardware.
Unfortunately, the documentation is a little obtuse, so I posted to the ganeti mailing list, and got the clues lined up.
First, you set a cluster exclusion tag, like so:
sudo gnt-cluster add-tags htools:iextags:role
This says “set up an exclusion tag, called role”
Then, when you create your instances, you add, for example: --tags role:prod-www
The instances created with the tag role:prod-www will be segregated onto different hardware nodes.
I did some testing to figure this out. First, as a control, create a bunch of small test instances:
sudo gnt-instance add ... ganeti-test0
sudo gnt-instance add ... ganeti-test1
sudo gnt-instance add ... ganeti-test2
sudo gnt-instance add ... ganeti-test3
sudo gnt-instance add ... ganeti-test4
Results:
$ sudo gnt-instance list | grep ganeti-test
ganeti-test0 kvm snf-image+default ganeti06-29 running 1.0G
ganeti-test1 kvm snf-image+default ganeti06-29 running 1.0G
ganeti-test2 kvm snf-image+default ganeti06-09 running 1.0G
ganeti-test3 kvm snf-image+default ganeti06-32 running 1.0G
ganeti-test4 kvm snf-image+default ganeti06-24 running 1.0G
As expected, some overlap in service nodes.
Next, delete the test instances, set a cluster exclusion tag for “role” and re-create the instances:
sudo gnt-cluster add-tags htools:iextags:role
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test0
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test1
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test2
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test3
sudo gnt-instance add ... --tags role:ganeti-test ganeti-test4
Results?
$ sudo gnt-instance list | grep ganeti-test
ganeti-test0 kvm snf-image+default ganeti06-29 running 1.0G
ganeti-test1 kvm snf-image+default ganeti06-09 running 1.0G
ganeti-test2 kvm snf-image+default ganeti06-32 running 1.0G
ganeti-test3 kvm snf-image+default ganeti06-24 running 1.0G
ganeti-test4 kvm snf-image+default ganeti06-23 running 1.0G
Yay! The instances are allocated to five distinct nodes!
But am I sure I understand what I am doing? Nuke the instances and try another example: 2x “www” instances and 3x “app” instances:
sudo gnt-instance add ... --tags role:prod-www ganeti-test0
sudo gnt-instance add ... --tags role:prod-www ganeti-test1
sudo gnt-instance add ... --tags role:prod-app ganeti-test2
sudo gnt-instance add ... --tags role:prod-app ganeti-test3
sudo gnt-instance add ... --tags role:prod-app ganeti-test4
What do we get?
$ sudo gnt-instance list | grep ganeti-test
ganeti-test0 kvm snf-image+default ganeti06-29 running 1.0G # prod-www
ganeti-test1 kvm snf-image+default ganeti06-09 running 1.0G # prod-www
ganeti-test2 kvm snf-image+default ganeti06-29 running 1.0G # prod-app
ganeti-test3 kvm snf-image+default ganeti06-32 running 1.0G # prod-app
ganeti-test4 kvm snf-image+default ganeti06-24 running 1.0G # prod-app
Yes! The first two instances are allocated to different nodes, then when the tag changes to prod-app, ganeti goes back to ganeti06-29 to allocate an instance.
Feedback Welcome
Link:
https://dannyman.toldme.com/2017/01/27/duct-tape-ops/
Yesterday we tried out Slack’s new thread feature, and were left scratching our heads over the utility of that. Someone mused that Slack might be running out of features to implement, and I recalled Zawinski’s Law:
Every program attempts to expand until it can read mail. Those programs which cannot so expand are replaced by ones which can.
I think this is a tad ironic for Slack, given that some people believe that Slack makes email obsolete and useless. Anyway, I had ended up on Jamie Zawiski’s (jwz) Wikipedia entry and there was this comment about jwz’s law:
Eric Raymond comments that while this law goes against the minimalist philosophy of Unix (a set of “small, sharp tools”), it actually addresses the real need of end users to keep together tools for interrelated tasks, even though for a coder implementation of these tools are clearly independent jobs.
This led to The Duct Tape Programmer, which I’ll excerpt:
Sometimes you’re busy banging out the code, and someone starts rattling on about how if you use multi-threaded COM apartments, your app will be 34% sparklier, and it’s not even that hard, because he’s written a bunch of templates, and all you have to do is multiply-inherit from 17 of his templates, each taking an average of 4 arguments … your eyes are swimming.
And the duct-tape programmer is not afraid to say, “multiple inheritance sucks. Stop it. Just stop.”
You see, everybody else is too afraid of looking stupid … they sheepishly go along with whatever faddish programming craziness has come down from the architecture astronauts who speak at conferences and write books and articles and are so much smarter than us that they don’t realize that the stuff that they’re promoting is too hard for us.
“At the end of the day, ship the fucking thing! It’s great to rewrite your code and make it cleaner and by the third time it’ll actually be pretty. But that’s not the point—you’re not here to write code; you’re here to ship products.”
jwz wrote a response in his blog:
To the extent that he puts me up on a pedestal for merely being practical, that’s a pretty sad indictment of the state of the industry.
In a lot of the commentary surrounding his article elsewhere, I saw all the usual chestnuts being trotted out by people misunderstanding the context of our discussions: A) the incredible time pressure we were under and B) that it was 1994. People always want to get in fights over the specifics like “what’s wrong with templates?” without realizing the historical context. Guess what, you young punks, templates didn’t work in 1994.
As an older tech worker, I have found that I am more “fad resistant” than I was in my younger days. There’s older technology that may not be pretty but I know it works, and there’s new technology that may be shiny, but immature, and will take a lot of effort to get working. As time passes, shiny technology matures and becomes more practical to use.
(I am looking forward to trying “Kubernetes in a Can”)
Feedback Welcome
Link:
https://dannyman.toldme.com/2016/08/24/vms-vs-containers/
I’ve been a SysAdmin for … since the last millennium. Long enough to see certain fads come and go and come again. There was a time when folks got keen on the advantages of chroot jails, but that time faded, then resurged in the form of containers! All the rage!
My own bias is that bare metal systems and VMs are what I am used to: a Unix SysAdmin knows how to manage systems! The advantages and desire for more contained environments seems to better suit certain types of programmers, and I suspect that the desire for chroot-jail-virtualenv-containers may be a reflection of programming trends.
On the one hand, you’ve got say C and Java … write, compile, deploy. You can statically link C code and put your Java all in a big jar, and then to run it on a server you’ll need say a particular kernel version, or a particular version of Java, and some light scaffolding to configure, start/stop and log. You can just write up a little README and hand that stuff off to the Ops team and they’ll figure out the mysterious stuff like chmod and the production database password. (And the load balancer config..eek!)
On the other hand, if you’re hacking away in an interpreted language: say Python or R, you’ve got a growing wad of dependencies, and eventually you’ll get to a point where you need the older version of one dependency and a bleeding-edge version of another and keeping track of those dependencies and convincing the OS to furnish them all for you … what comes in handy is if you can just wad up a giant tarball of all your stuff and run it in a little “isolated” environment. You don’t really want to get Ops involved because they may laugh at you or run in terror … instead you can just shove the whole thing in a container, run that thing in the cloud, and now without even ever having to understand esoteric stuff like chmod you are now DevOps!
(Woah: Job Security!!)
From my perspective, containers start as a way to deploy software. Nowadays there’s a bunch of scaffolding for containers to be a way to deploy and manage a service stack. I haven’t dealt with either case, and my incumbent philosophy tends to be “well, we already have these other tools” …
Container Architecture is basically just Legos mixed with Minecraft (CC: Wikipedia)
Anyway, as a Service Provider (… I know “DevOps” is meant to get away from that ugly idea that Ops is a service provider …) I figure if containers help us ship the code, we’ll get us some containers, and if we want orchestration capabilities … well, we have what we have now and we can look at bringing up other new stuff if it will serve us better.
ASIDE: One thing that has put me off containers thus far is not so much that they’re reinventing the wheel, so much that I went to a DevOps conference a few years back and it seemed every single talk was about how we have been delivered from the evil sinful ways of physical computers and VMs and the tyranny of package managers and chmod and load balancers and we have found the Good News that we can build this stuff all over in a new image and it will be called Docker or Mesos or Kubernetes but careful the API changed in the last version but have you heard we have a thing called etcd which is a special thing to manage your config files because nobody has ever figured out an effective way to … honestly I don’t know for etcd one way or another: it was just the glazed, fervent stare in the eyes of the guy who was explaining to me the virtues of etcd …
It turns out it is not just me who is a curmudgeonly contrarian: a lot of people are freaked out by the True Believers. But that needn’t keep us from deploying useful tools, and my colleague reports that Kubernetes for containers seems awfully similar to the Ganeti we are already running for VMs, so let us bootstrap some infrastructure and provide some potentially useful services to the development team, shall we?
Feedback Welcome
Link:
https://dannyman.toldme.com/2016/07/01/ansible-use-ssh-add-to-set-authorized_key/
Background: you use SSH and ssh-agent and you can get a list of keys you presently have “ready to fire” via:
djh@djh-MBP:~/devops$ ssh-add -l
4096 SHA256:JtmLhsoPoSfBsFnrIsZc6XNScJ3ofghvpYmhYGRWwsU .ssh/id_ssh (RSA)
Aaaand, you want to set up passwordless SSH for the remote hosts in your Ansible. There are lots of examples that involve file lookups for blah blah blah dot pub but why not just get a list from the agent?
A playbook:
- hosts: all
gather_facts: no
tasks:
- name: Get my SSH public keys
local_action: shell ssh-add -L
register: ssh_keys
- name: List my SSH public keys
debug: msg="{{ ssh_keys.stdout }}"
- name: Install my SSH public keys on Remote Servers
authorized_key: user={{lookup('env', 'USER')}} key="{{item}}"
with_items: "{{ ssh_keys.stdout }}"
This is roughly based on a Stack Overflow answer.
The two tricky bits are:
1) Running a local_action to get a list of SSH keys.
2) Doing with_items to iterate if there are multiple keys.
A bonus tricky bit:
3) You may need to install sshpass if you do not already have key access to the remote servers. Last I knew, the brew command on Mac OS will balk at you for trying to install this.
Feedback Welcome
Link:
https://dannyman.toldme.com/2016/04/21/ubuntu-16-04-reactions/

Xerus: an African ground squirrel. CC: Wikipedia
I have misplaced my coffee mug. I’m glad to hear Ubuntu 16.04 LTS is out. “Codenamed ‘Xenial Xerus'” because computer people don’t already come off as a bunch of space cadets. Anyway, an under-caffeinated curmudgeon’s take:
The Linux kernel has been updated to the 4.4.6 longterm maintenance
release, with the addition of ZFS-on-Linux, a combination of a volume
manager and filesystem which enables efficient snapshots, copy-on-write
cloning, continuous integrity checking against data corruption, automatic
filesystem repair, and data compression.
Ah, ZFS! The last word in filesystems! How very exciting that after a mere decade we have stable support for it on Linux.
There’s a mention of the desktop: updates to LibreOffice and “stability improvements to Unity.” I’m not going to take that bait. No sir.
Ubuntu Server 16.04 LTS includes the Mitaka release of OpenStack, along
with the new 2.0 versions of Juju, LXD, and MAAS to save devops teams
time and headache when deploying distributed applications – whether on
private clouds, public clouds, or on developer laptops.
I honestly don’t know what these do, but my hunch is that they have their own overhead of time and headache. Fortunately, I have semi-automated network install of servers, Ganeti to manage VMs, and Ansible to automate admin stuff, so I can sit on the sidelines for now and hope that by the time I need it, Openstack is mature enough that I can reap its advantages with minimal investment.
Aside: My position on containers is the same position I have on Openstack, though I’m wondering if the containers thing may blow over before full maturity. Every few years some folks get excited about the possibility of reinventing their incumbent systems management paradigms with jails, burn a bunch of time blowing their own minds, then get frustrated with the limitations and go back to the old ways. We’ll see.
Anyway, Ubuntu keeps delivering:
Ubuntu 16.04 LTS introduces a new application format, the ‘snap’, which
can be installed alongside traditional deb packages. These two packaging
formats live quite comfortably next to one another and enable Ubuntu to
maintain its existing processes for development and updates.
YES YES YES YES YES YES YES OH snap OH MY LERD YES IF THERE IS ONE THING WE DESPERATELY NEED IT IS YET ANOTHER WAY TO MANAGE PACKAGES I AM TOTALLY SURE THESE TWO PACKAGING FORMATS WILL LIVE QUITE COMFORTABLY TOGETHER next to the CPANs and the CRANs and the PIPs and the … don’t even ask how the R packages work …
Further research reveals that they’ve replaced Python 2 with Python 3. No mention of that in the email announcement. I’m totally sure this will not yield any weird problems.
Feedback Welcome
Link:
https://dannyman.toldme.com/2016/02/09/tech-tip-self-documenting-config-files/
One of my personal “best practices” is to leave myself and my colleagues hints as to how to get the job done. Plenty of folks may be aware that they need to edit /etc/exports to add a client to an NFS server. I would guess that the filename and convention is decades old, but who among us, even the full-time Unix guy, recalls that you then need to reload the nfs-kernel-server process?
For example:
0-11:04 djh@fs0 ~$ head -7 /etc/exports
# /etc/exports: the access control list for filesystems which may be exported
# to NFS clients. See exports(5).
#
# ***** HINT: After you edit this file, do: *****
# sudo service nfs-kernel-server reload
# ***** HINT: run the command on the previous line! *****
#
Feedback Welcome
Link:
https://dannyman.toldme.com/2016/01/02/windows-10/
The other day I figured to browse Best Buy. I spied a 15″ Toshiba laptop, the kind that can pivot the screen 180 degrees into a tablet. With a full sized keyboard. And a 4k screen. And 12GB of RAM. For $1,000. The catch? A non-SSD 1TB hard drive and stock graphics. And … Windows 10.
But it appealed to me because I’ve been thinking I want a computer I can use on the couch. My home workstation is very nice, a desktop with a 4k screen, but it is very much a workstation. Especially because of the 4k screen it is poorly suited to sitting back and browsing … so, I went home, thought on it over dinner, then drove back to the store and bought a toy. (Oh boy! Oh boy!!)
Every few years I flirt with Microsoft stuff — trying to prove that despite the fact I’m a Unix guy I still have an open mind. I almost usually throw up my hands in exasperation after a few weeks. The only time I ever sort of appreciated Microsoft was around the Windows XP days, it was a pretty decent OS managing folders full of pictures. A lot nicer than OS X, anyway.
This time, out of the gate, Windows 10 was a dog. The non-SSD hard drive slowed things down a great deal. Once I got up and running though, it isn’t bad. It took a little getting used to the sluggishness — a combination of my adapting to the trackpad mouse thing and I swear that under load the Windows UI is less responsive than what I’m used to. The 4k stuff works reasonably well … a lot of apps are just transparently pixel-doubled, which isn’t always pretty but it beats squinting. I can flip the thing around into a landscape tablet — which is kind of nice, though, given its size, a bit awkward — for reading. I can tap the screen or pinch around to zoom text. The UI, so far, is back to the good old Windows-and-Icons stuff old-timers like me are used to.
Mind you, I haven’t tried anything as nutty as setting up OpenVPN to auto-launch on user login. Trying to make that happen for one of my users at work on Windows 8 left me twitchy for weeks afterward.
Anyway, a little bit of time will tell .. I have until January 15 to make a return. The use case is web browsing, maybe some gaming, and sorting photos which are synced via Dropbox. This will likely do the trick. As a little bonus, McAfee anti-virus is paid for for the first year!
I did try Ubuntu, though. Despite UEFI and all the secure boot crud, Ubuntu 15.10 managed the install like it was nothing, re-sizing the hard drive and all. No driver issues … touchscreen even worked. Nice! Normally, I hate Unity, but it is okay for a casual computing environment. Unlike Windows 10, though, I can’t three-finger-swipe-up to show all the windows. Windows+W will do that but really … and I couldn’t figure out how to get “middle mouse button” working on the track pad. For me, probably 70% of why I like Unix as an interface is the ease of copy-paste.
But things got really dark when I tried to try KDE and XFCE. Installing either kubuntu-desktop or xubuntu-desktop actually made the computer unusable. The first had a weird package conflict that caused X to just not display at all. I had to boot into safe mode and manually remove the kubuntu dependencies. The XFCE was slightly less traumatic: it just broke all the window managers in weird ways until I again figured out how to manually remove the dependencies.
It is just as easy to pull up a Terminal on Windows 10 or Ubuntu … you hit Start and type “term” but Windows 10 doesn’t come with an SSH client, which is all I really ask. From what I can tell, my old friend PuTTY is still the State of the Art. It is like the 1990s never died.
Ah, and out of the gate, Windows 10 allows you multiple desktops. Looks similar to Mac. I haven’t really played with it but it is a heartening sign.
And the Toshiba is nice. If I return it I think I’ll look for something with a matte screen and maybe actual buttons around the track pad so that if I do Unix it up, I can middle-click. Oh, and maybe an SSD and nicer graphics … but you can always upgrade the hard drive after the fact. I prefer matte screens, and being a touch screen means this thing hoovers up fingerprints faster than you can say chamois.
Maybe I’ll try FreeBSD on the Linux partition. See how a very old friend fares on this new toy. :)
Feedback Welcome
Link:
https://dannyman.toldme.com/2015/11/11/variability-of-hard-drive-speed/
Munin gives me this beautiful graph:
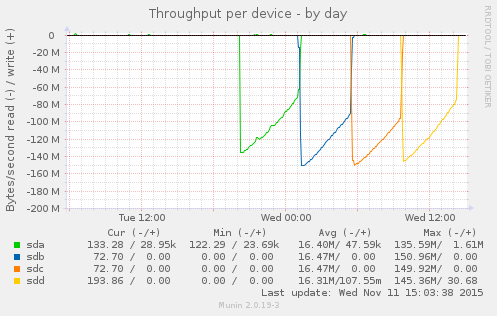
This is the result of:
$ for s in a b c d; do echo ; echo sd${s} ; sudo dd if=/dev/sd${s} of=/dev/null; done
sda
3907029168+0 records in
3907029168+0 records out
2000398934016 bytes (2.0 TB) copied, 17940.3 s, 112 MB/s
sdb
3907029168+0 records in
3907029168+0 records out
2000398934016 bytes (2.0 TB) copied, 15457.9 s, 129 MB/s
sdc
3907029168+0 records in
3907029168+0 records out
2000398934016 bytes (2.0 TB) copied, 15119.4 s, 132 MB/s
sdd
3907029168+0 records in
3907029168+0 records out
2000398934016 bytes (2.0 TB) copied, 16689.7 s, 120 MB/s
The back story is that I had a system with two bad disks, which seems a little weird. I replaced the disks and I am trying to kick some tires before I put the system back into service. The loop above says “read each disk in turn in its entirety.” Prior to replacing the disks, a loop like the above would cause the bad disks, sdb, and sdc, to abort read before completing the process.
The disks in this system are 2TB 7200RPM SATA drives. sda and sdd are Western Digital, while sdb and sdc are HGST. This is in no way intended as a benchmark, but what I appreciate is the consistent pattern across the disks: throughput starts high and then gradually drops over time. What is going on? Well, these are platters of magnetic discs spinning at a constant speed. When you read a track on the outer part of the platter, you get more data than when you read from closer to the center.
I appreciate the clean visual illustration of this principle. On the compute cluster, I have noticed that we are more likely to hit performance issues when storage capacity gets tight. I had some old knowledge from FreeBSD that at a certain threshold, the OS optimizes disk writes for storage versus speed. I don’t know if Linux / ext4 operates that way. It is reassuring to understand that, due to the physical properties, traditional hard drives slow down as they fill up.
Feedback Welcome
Link:
https://dannyman.toldme.com/2015/04/23/virsh-migrate-local-storage-live/
In my previous post I lamented that it seemed I could not migrate a VM between virtual hosts without shared storage. This is incorrect. I have just completed a test run based on an old mailing list message:
ServerA> virsh -c qemu:///system list
Id Name State
----------------------------------------------------
5 testvm0 running
ServerA> virsh -c qemu+ssh://ServerB list # Test connection to ServerB
Id Name State
----------------------------------------------------
The real trick is to work around a bug whereby the target disk needs to be created. So, on ServerB, I created an empty 8G disk image:
ServerB> sudo dd if=/dev/zero of=/var/lib/libvirt/images/testvm0.img bs=1 count=0 seek=8G
Or, if you’re into backticks and remote pipes:
ServerB> sudo dd if=/dev/zero of=/var/lib/libvirt/images/testvm0.img bs=1 count=0 seek=`ssh ServerA ls -l /var/lib/libvirt/images/testvm0.img | awk '{print $5}'`
Now, we can cook with propane:
ServerA> virsh -c qemu:///system migrate --live --copy-storage-all --persistent --undefinesource testvm0 qemu+ssh://ServerB/system
This will take some time. I used virt-manager to attach to testvm0’s console and ran a ping test. At the end of the procedure, virt-manager lost console. I reconnected via ServerB and found that the VM hadn’t missed a ping.
And now:
ServerA> virsh -c qemu+ssh://ServerB/system list
Id Name State
----------------------------------------------------
4 testvm0 running
Admittedly, the need to manually create the target disk is a little more janky than I’d like, but this is definitely a nice proof of concept and another nail in the coffin of NAS being a hard dependency for VM infrastructure. Any day you can kiss expensive, proprietary SPOF dependencies goodbye is a good day.
Feedback Welcome
Link:
https://dannyman.toldme.com/2015/04/22/virt-manager-hell-yeah/
I may have just had a revelation.
I inherited a bunch of ProxMox. It is a rather nice, freemium (nagware) front-end to virtualization in Linux. One of my frustrations is that the local NAS is pretty weak, so we mostly run VMs on local disk. That compounds with another frustration where ProxMox doesn’t let you build local RAID on the VM hosts. That is especially sad because it is based on Debian and at least with Ubuntu, building software RAID at boot is really easy. If only I could easily manage my VMs on Ubuntu . . .
Well, turns out, we just shake the box:
On one or more VM hosts, check if your kernel is ready:
sudo apt-get install cpu-checker
kvm-ok
Then, install KVM and libvirt: (and give your user access..)
sudo apt-get install qemu-kvm libvirt-bin ubuntu-vm-builder bridge-utils
sudo adduser `id -un` libvirtd
Log back in, verify installation:
virsh -c qemu:///system list
And then, on your local Ubuntu workstation: (you are a SysAdmin, right?)
sudo apt-get install virt-manager
Then, upon running virt-manager, you can connect to the remote host(s) via SSH, and, whee! Full console access! So far the only kink I have had to iron is that for guest PXE boot you need to switch Source device to vtap. The system also supports live migration but that looks like it depends on a shared network filesystem. More to explore.
UPDATE: You CAN live migrate between local filesystems!
It will get more interesting to look at how hard it is to migrate VMs from ProxMox to KVM+libvirt.
Feedback Welcome
Link:
https://dannyman.toldme.com/2014/05/15/vmware-retina-thunderbolt-constant-resolution/
Apple ships some nice hardware, but the Mac OS is not my cup of tea. So, I run Ubuntu (kubuntu) within VMWare Fusion as my workstation. It has nice features like sharing the clipboard between host and guest, and the ability to share files to the guest. Yay.
At work, I have a Thunderbolt display, which is a very comfortable screen to work at. When I leave my desk, the VMWare guest transfers to the Retina display on my Mac. That is where the trouble starts. You can have VMWare give it less resolution or full Retina resolution, but in either case, the screen size changes and I have to move my windows around.
The fix?
1) In the guest OS, set the display size to: 2560×1440 (or whatever works for your favorite external screen …)
2) Configure VMWare, per https://communities.vmware.com/message/2342718
2.1) Edit Library/Preferences/VMware Fusion/preferences
Set these options:
pref.autoFitGuestToWindow = "FALSE"
pref.autoFitFullScreen = "stretchGuestToHost"
2.2) Suspend your VM and restart Fusion.
Now I can use Exposé to drag my VM between the Thunderbolt display and the Mac’s Retina display, and back again, and things are really comfortable.
The only limitation is that since the aspect ratios differ slightly, the Retina display shows my VM environment in a slight letterbox, but it is not all that obvious on a MacBook Pro.
Feedback Welcome
Older Stuff »
Site Archive





{kind=link}
{kind=link}
{kind=link}