Notes From Atlassian Summit 2013
Two weeks ago, I attended Atlassian Summit 2013 in San Francisco. Â This is an opportunity to train, network, and absorb propaganda about Atlassian products (JIRA, Greenhopper, Confluence, &c.) and ecosystem partners. Â I thought I would share a summary of some of the notes I took along the way, for anyone who might find interest:
At the Keynote, Atlassian launched some interesting products:
As time passes, the ticket gets crankier at you in real time about the SLA.
Jira Service Desk
Jira Service Desk is an extension to JIRA 6 oriented around IT needs.  The interesting features include:
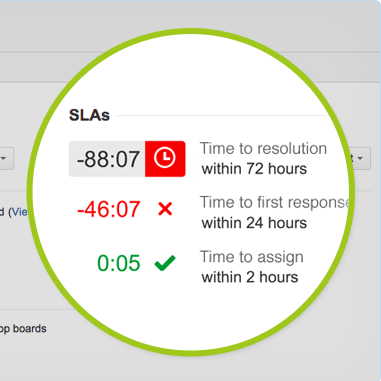
- Customer Portal with integrated KB search
- Real-time visibility of ticket SLA status
The first thing helps people get their work done, and the second is manager catnip.
Confluence Knowledge Base
Confluence 5.3 features a shake-the-box Knowledge Base setup:
- Improved template system — “blueprints” for different article types
- Real-time search portal which integrates with JIRA Service Desk
- My Questions: enforcing KB link with JIRA workflow and identifying “use count” as an article search metric
Other Stuff I looked into:
REST and Webhooks
There was a presentation on JIRA’s REST API, and mention of Webhooks.
REST is really easy to use.  For example, hit https://jira.atlassian.com/rest/api/latest/issue/JRA-9
There’s API docs here:Â https://docs.atlassian.com/jira/REST/
Another feature for tight integration is Webhooks: you can configure JIRA so that certain issue actions trigger a hit to a remote URL. Â This is generally intended for building apps around JIRA. Â We might use this to implement Nagios ACKs.
Atlassian Connect
I haven’t looked too deeply as this is a JIRA 6 feature, but Atlassian Connect promises to be a new method of building JIRA extensions that is lighter-weight than their traditional plugin method.  (Plugins want you to set up Eclipse and build a Java Dev environment in your workstation… Connect sounds like just build something in your own technology stack around REST and Webhooks)
Cultivating Content: Designing Wiki Solutions that Scale
Rebecca Glassman, a tech writer at Opower, gave a really engaging talk that addresses a problem that seems commonplace: how to tame the wiki jungle! Â Her methodology went something like this:
- Manage the wiki like it is a product: interview stakeholders, get some metrics, do UX testing
- Metrics: Google Analytics, View Tracker Macro, Usage Macro
- UX results at Opower revealed more reliance on Table of Contents vs Search (55%) and that users skip past top-level pages, so you don’t want to put content just on there
- In search, users only look at the first 2-3 results before giving up
- They engaged some users to track the questions they had and their success at getting answers from the wiki
- The Docs people (2) built an “answer desk” situation where they took in Questions from across the company, and tracked their progress writing answers on a Kanban board
As they better learned user needs and what sort of knowledge there was, they built “The BOOK” (Body of Opower Knowledge) based on a National Parks model:
- Most of the wiki is a vast wilderness, which you are free to explore
- The BOOK is the nice, clean visitors center to help take care of most of your needs and help you prepare for your trek into the wilderness
- The BOOK is a handbook, in its own space, with its own look-and-feel, and edits are welcome, but they are vetted by the Docs team via Ad Hoc Workflows
- By having tracked Metrics from the get-go, they can quantify the utility of The BOOK …
(I have some more notes on how they built, launched, and promoted The BOOK. Â The problem they tackled sounds all to familiar and her approach is what I have always imagined as the sort of way to go.)
Ad Hoc Canvas
The Ad Hoc Canvas plugin for Confluence caught my eye.  At first glance, it is like Trello, or Kanban, where you fill out little cards and drag them around to track things.  But it has options to organize the information in different ways depending on the task at hand: wherever you are using a spreadsheet to track knowledge or work, Ad Hoc Canvas might be a much better solution.  Just look at the videos and you get an idea . . .
The Dark Art of Performance Tuning
Adaptavist gave a presentation on performance analysis of JIRA and Confluence. Â It was fairly high-level but the gist of this is that you want to monitor and trend the state of the JVM: memory, heap, garbage collection, filehandles, database connections, &c. Â He had some cool graphs of stuff like garbage collection events versus latency that had helped them to analyze issues for clients. Â One consideration is that each plugin and each code revision to a plugin brings a bunch of new code into the pool with its own potential for issues. Â Ideally, you can set up a load testing environment for your staging system. Â Short of that, the more system metrics that you can track, you can upgrade plugins one at a time and watch for any effects. Â As an example, one plugin upgrade went from reserving 30 database connections to reserving 150 database connections, and that messed up performance because the rest of the system would become starved of available database connections. Â (So, they figured that out and increased that resource..)
tl;dr: JIRA Performance Tuning is a variation of managing other JVM Applications
Collaboration For Executives
I popped in on this session near the end, but the takeaway for anyone who wants to deliver effective presentations to upper management are:
- Know Your Audience
- Own Your Data
- Tell your Story
- Join Toastmasters International
The presenter’s narrative was driven by an initial need to capture executive buy-in that their JIRA system was critical to business function and needed adequate resourcing.
Comment
Tiny Print:
<a href="" title=""> <abbr title=""> <acronym title=""> <b> <blockquote cite=""> <cite> <code> <del datetime=""> <em> <i> <q cite=""> <s> <strike> <strong>