Balancing 3-Phase Power
I have some racks in a data center that were designed to use 3-phase PDUs. This allows for greater density, since a 3-phase circuit delivers more watts. The way three-phase works is that the PDU breaks the circuit into three branches, and each branch is split across two of the legs. Something like:
Branch A: leg X->Y
Branch B: leg Y->Z
Branch C: leg Z->X
The load needs to be balanced as evenly as possible across the three branches. When the PDU tells me the power draw on Branch A is say, 3A, I am really sure if that is because of equipment on Branch A or … Branch C? This only becomes a problem when one branch reports chronic overloading and I want to balance the loads.
I chatted with a friend who has a PhD in this stuff. He said that if my servers don’t all have similar characteristics, then the math says I want to randomly distribute the load. That is hard to do on an existing rack.
I came up with an alternative approach. Most of my servers fall into clusters of similar hardware and what I would call a “load profile.” I had a rack powered by two unbalanced 3-phase circuits. I counted through the rack’s server inventory and classified each host into a series of cohorts based on their hardware and load profile. Two three-phase circuits gives me six branches to work with, so I divided the total by six to come up with a “branch quota.” Something like:
<= 2 hadoop node, hardware type A <= 2 hadoop node, hardware type B 1 spark node, hardware type A 1 spark node, hardware type C 1 misc node, hardware type C
I then sat down with a pad and paper, one circuit on either side of the sheet, and wrote down what servers I had, and where the circuit was relative to quota. So, one circuit might have started off as:
Circuit A, Branch XY: INVENTORY hadoopA-12 hadoopA-13 hadoopA-14 sparkA-5 miscC-5 QUOTA hadoopA: RM 1 hadoopB: ADD 2 sparkA: -- sparkC: ADD 1 misc: --
I then moved servers around, updating each branch circuit with pencil and eraser as I went, like a diligent Dungeon Master. (And also, very important: the PDU receptacle configuration.)
The end result:
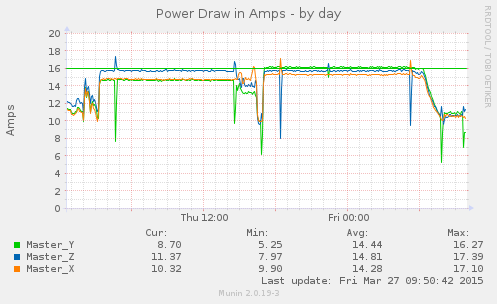
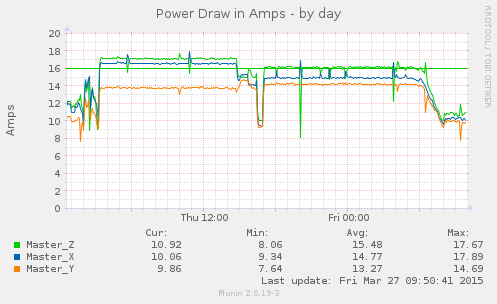
I started moving servers around Thu 15:00, and was done about 16:30, which is also when the hadoop cluster went idle. It kicked back up again at 17:00, and started spinning down around midnight.
What is important is to keep sustained load on the branches under the straight green line, which represents 80% of circuit capacity. You can see that on the left, especially the second circuit had two branches running “hot” and after the re-balancing the branch loads fly closer together, and top off at the green line.